On today’s post, I will share how to Authenticate to VCF Automation 9 API without having to rely on a GUI generated API token.
The implementation of this API token is one of the changes that happened with the change from Aria Automation 8.18 (from now, vRA8) to VCF Automation 9 (from now, VCFA 9), and it is in line with how authentication is handled in Cloud Director.
The problem
In vRA 8, you generated a refresh token with your username and password, and then you generate an access token from that refresh token. The important part is that you could start with username and password, and finish up that workflow fully authenticated to vRA 8 – It was very straightforward
However, in VCFA 9, the solution is not so straightforward, at least at a first glance
Enter VCF SSO (vIDB)
VCF 9 allows you to have a single identity solution across all the VCF Stack (and this includes the fleet components)
This was not the case entirely in VCF 5.x – “vRealize Suite” components could use Identity Manager, and so could NSX, but it was not the case for vCenter (and we also had things that are now deprecated such as ELM that prevented this from happening
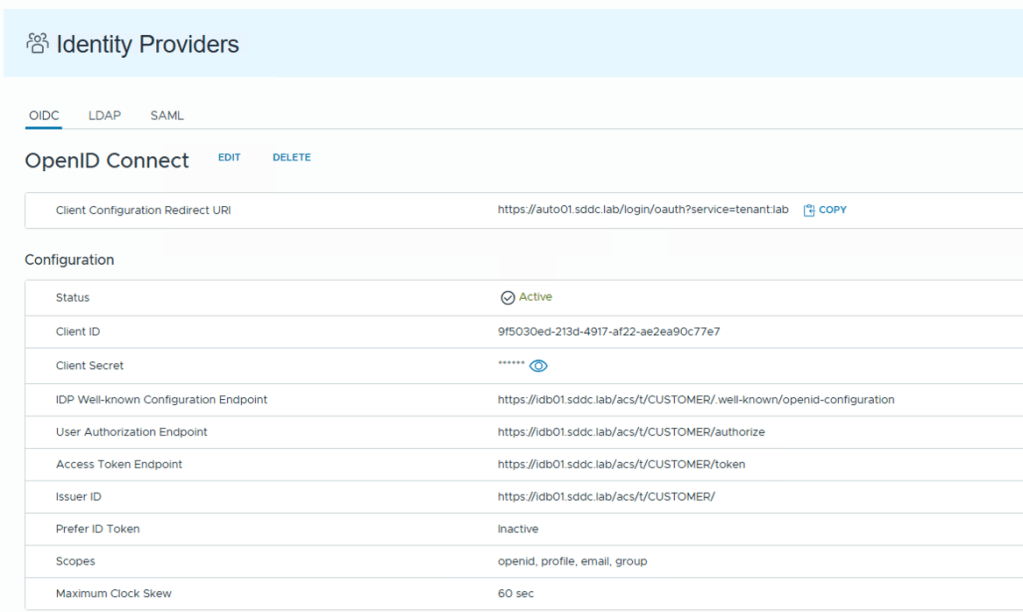
In VCFA 9, you can configure SSO for each tenant by using OIDC – and this is the preferred and recommended authentication method so that you can centralize all authentication in vIDB (VCF SSO)
OIDC Integration in VCFA
However, the VCF SSO integration does not allow you to start an authentication workflow with username and password and finish the workflow with an API token like we could do in vRA 8…
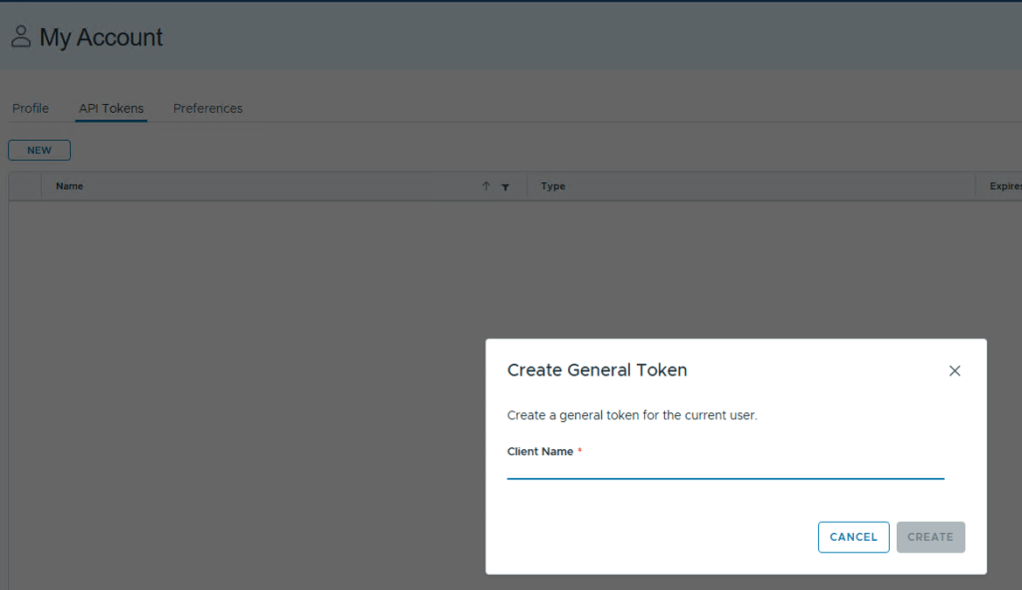
The process requires to have created an API token through the GUI first.
So for example, for service accounts, you need to log on via GUI (with username and password) to then create that API token, and then persist / save that API token somewhere, which is only used by that service account.
You see where I’m going with this…
Creating GUI (API) Token
If you manage multiple VCFA instances in the same domain (think of an environment with multiple VCF Fleets) you can see where this can become problematic.
Keeping track of multiple tokens for the each user, and map those to every VCFA instance is not ideal.
The Solution!
Unfortunately, the solution is not as pretty as it sounds, because it means we cannot leverage VCF SSO for the service accounts that we want to authenticate with using username and password.
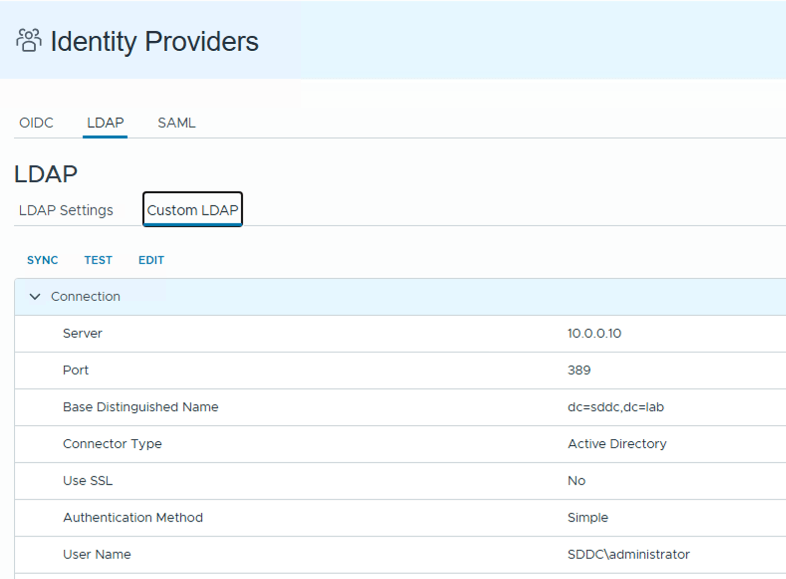
Thankfully, VCFA also supports LDAP!
So we can configure, in the same tenant, an LDAP configuration (pointing to the same LDAP/AD that the VCF SSO connection is using, giving us access to the same users and groups)
Configuring LDAP access in VCFA
Question is: If we are using the same domain, why does LDAP work and VCF SSO (OIDC) doesn’t? The problem relies in the API used to generate the token…
The API call is a POST to “https://VCFA_URL/cloudapi/1.0.0/sessions” and it takes a base64 encoded username and password pair.
However, the user in the header needs to be in the format of “username@domain:password” – with the caveat that the domain here is not your AD domain, it is the tenant! – in this case, my VM Apps tenant is called “lab” .
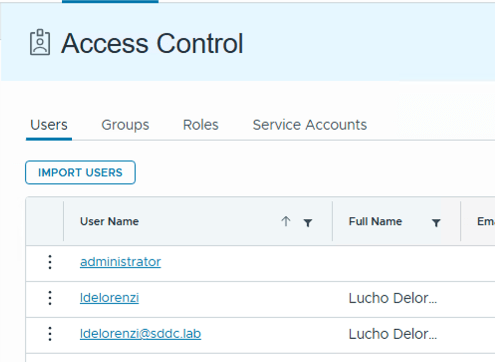
Here is the key difference between how VCF SSO and LDAP work. The users collected via VCF SSO have the full name, while LDAP only collects the shortname of the user.
First user is collected via LDAP, second user is collected via OIDC (VCF SSO)
Since you cannot do “ldelorenzi@sddc.lab@lab“, you’re forced to use LDAP
While we cannot get around of the GUI generated API token for VCF SSO integration, the fact that we can circumvent this limitation by using LDAP makes this a viable approach for authenticating to VCFA 9 via API.
You can continue to use all your custom front-ends, scripts, workflows, in a very similar way to what you used in the past, which is a good thing. No need to reinvent the wheel!
Hope you found this useful! See you in the comments!
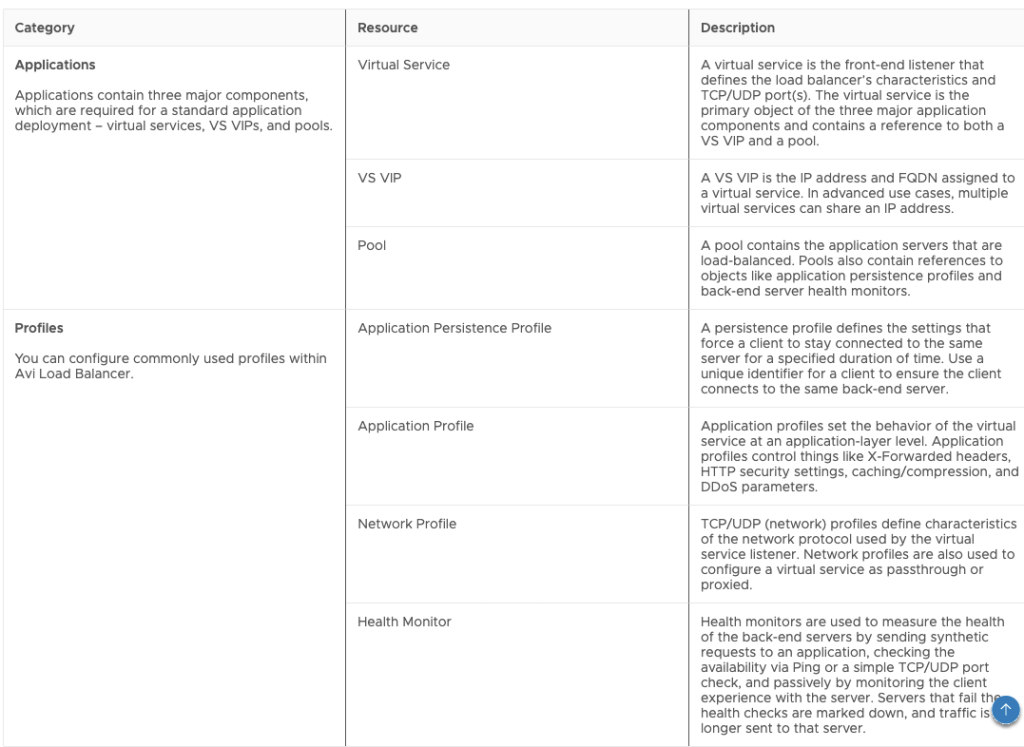
On today’s post, we’re going to talk about the newly released feature in Aria Automation 8.16.1 which is the native integration with the AVI Load Balancer (also called Advanced Load Balancer, and from now on this post, ALB) by using a NSX-T Load Balancer as an example and starting point.
The goal of this post will be for you to be able to operate with the AVI Load Balancer from Aria Automation in the same way that you can do today with the NSX-T Load Balancer.
On that document, in addition to a list of steps, you will also see what permissions are needed by the Aria Automation user that will be interacting with ALB.
It is important to configure these Cloud Accounts with the same capability tags that the vCenters in the same location (and that will be hosting these resources) have.
While there is a native ‘association’ between NSX-T and vCenter, that concept does not currently exist with ALB. If you plan on having more than one ALB Cloud Account in your Aria Automation instance, and you plan to leverage the allocation helper construct (which we will talk about later) make sure the tagging is in place.
This will create a Cloud Zone in Aria Automation as well. Make sure you are adding this Cloud Zone to the projects you plan to consume (as stated in the documentation above). This will all come into play later.
Assumptions on the ALB side
For the purposes of this blog post, I’m going to take the following assumptions on the ALB configuration side, which need to be in place for the integration to work.
There is a NSX-T Cloud Configured with the same vCenter and NSX-T account that you will be using in Aria Automation
There is at least one IPAM profile assigned to the NSX-T cloud with at least one usable VIP network profile configured for allocating VIP IPs
This VIP network profile name matches the network name in NSX-T
There is a Service Engine group correctly configured
Now that everything is set up on the Aria Automation side (and ALB side) let’s move on to our use case!
NSX-T Template
Let’s take a look at the following NSX-T LB YAML Code
Two virtual servers. One with TCP Port 1000, and another one with HTTP Port 80. Load Balancer Algorithm used for each of them is different
Each virtual server has it’s own specific health check configuration as well as an application persistence configuration
Load Balancer is using an existing NSX network in the deployment
Load Balancer is taking the VM instances in the deployment as their pool members. Since VMs have a dynamic count, it is specified in that way in the assignment.
In addition to this, we’re going to need to use the Allocation Helper for the cloud zone, which is also an available resource in the canvas.
Now that we have all of this, what does our NSX-T example translate to, with regards to objects?
We’re going to need:
One VS VIP object for IP allocation (either static or dynamic)
One Pool object per route
One Virtual Service object per route
One Monitor object per each individual health check configuration
One Application Persistence object per each individual persistence configuration
One Cloud Zone Helper object for placement
I know this sounds like a handful, but we will explain how to build each of these objects below. ALB provides much greater flexibility with regards to features, but that comes with the tradeoff of complexity.
It might take us longer to build what looked simpler in NSX-T, but once we’re over that hurdle, the amount of new possibilities is much greater!
Building the ALB Objects
While I’m going to explain each how to build each object here, there is a resource that’s invaluable for building all of this, which is the Swagger documentation of the ALB API.
In the swagger documentation, you will be able to see each object’s schema model, as well as examples of creation. You might need to tweak and modify some of it to be able to use it in Aria Automation, but with some trial and error, success is very likely!
I will go about these objects in order by dependency – that means, an object has to be created first (it has to exist), to then be referenced by another object.
Cloud Zone Helper Object
This object will be used to apply constraint tags – In this example, I will match the tags that my VM objects have, so that there is matching with the vCenter – This one is pretty self explanatory, and it will be referenced by other objects
VSVIP requires a name – This is the name that you will see in the ALB console – you can set this to whatever name you want, but it makes sense to tie this to the deployment name so that you can identify it
description can also be anything
vrf_context_ref would be the name of the context ref in your NSX-T Cloud in ALB
tier1_lr is the path to the T1 Gateway in your NSX-T instance – this uses the relative path in the NSX-T API as it is not an ALB Object:
Note: this might change in future versions and might not be needed
account is the ALB cloud account that you’re going to use – here is where you reference the Cloud Zone Helper created before
vip is it’s own object, with the following properties
Since we’re only using a single VIP, vip_id would be 0
auto_allocate_ip is set to true because we want dynamic IP
auto_allocate_ip_type is set to V4_ONLY because we’re doing IPV4
enabled is set to true because we are enabling this VS VIP as we create it
ipam_network_subnet is an object with a network_ref that maps to a VIP network profile in ALB
Since this should match to a NSX-T network, we can use the network name in the deployment as an identifier
This would be different if you were using a dedicated VIP segment. If that is the case, you can reference a specific VIP network profile name by name instead of using the name of the network resource in the deployment
Monitor Objects
For this deployment, we will have two monitor objects – one for each health check configuration
These objects also require names. To maintain consistency, we will be using the deployment name as an identifier
Important – Since there will be more than one monitor, we’re using _NUMBER as an identifier as well. Then we can use the same numbering to map this to other objects (like Virtual Services, Pools or Profiles)
You can also see that I’m using the same numbering for the objects within the YAML. This helps maintain consistency and makes it easier to understand what maps to what.
account follows the same logic as in the VS VIP (and all the objects) – mapped to the Cloud Zone Helper object
monitor_port is the port that is being monitored
type is the monitor type – in this case, we have a HTTP and a TCP monitor
successful_checks, failed_checks and send_interval are self explanatory
http_request (which only shows up in the HTTP monitor) would be the method to use, and to what URL, in this case, we’re doing a GET to /
Application Persistence Objects
For this deployment, we will have two Application Persistence objects, one per application persistence configuration
Like every object, they need a name – following the same structure as the other objects
account also follows the same structure
persistence_type will depend on the type of persistence. We have one config for Source IP and one config for Cookie
The object with the properties will be dependent on the persistence_type
If you’re using Source IP persistence, the object will be ip_persistence_profile
ip_mask is the mask to be applied to the client IP. This is 0 because we’re not applying a mask
ip_persistent_timeout is the length of time before expiring the client’s persistence to a server, after its connections have been closed
If you’re using Cookie Persistence, the object will be http_cookie_persistence_profile
cookie_name is required and we can use the same naming structure as we use for the rest of the objects. I’m also making the number match to the number in the YAML resource for easier undertanding
timeout is the maximum lifetime of any session cookie
is_persistent_cookie controls the usage of the cookie as a session cookie even after the timeout, if the session is still open. With false, we’re allowing for this to happen
Pool Objects
For this deployment, we will have two Pool objects, one per route
name, account and description follow the same structure as the other objects
tier1_lr is used in the same way as in the VS VIP object
default_server_port is the default server port (would map to the internal port in the NSX-T Load Balancer)
health_monitor_refs is an array of monitor references. Since our monitors are different, we are only going to use one item in the array, and this reference maps to the numbering used in the monitors
This is why we kept numbering consistent – so MONITOR_1 maps to POOL_1 and MONITOR_2 maps to POOL_2
servers maps to the servers in the deployment – the syntax uses map_by to allow for clustering as well as both attributes needed by the ip object, which are addr and type
application_persistence_profile_ref maps to the application persistence object defined before
Same scenario with the monitor – We keep numbering consistent so PERSISTENCE_PROFILE_1 maps to POOL_1 and PERSISTENCE_PROFILE_2 maps to POOL_2
Virtual Services Objects
For this deployment, we will have two Virtual Services objects, one per route
name and account follow the same structure as in the other objects
vrf_context follows the same structure as in the VS VIP object
enabled is set to true because we want this service to be enabled
services is an array – but since we’re mapping this to a single pool, we will only have one service in the virtual service
We’re using the same port as the internal port, and enable_ssl is set to false
traffic_enabled is set to true to allow for traffic
vsvip_ref references the VS VIP object previously created – since there is a single VSVIP object, both virtual services will reference it
pool_ref references the pool that has the members for this service. Using the same numbering strategy as before, VIRTUALSERVICE_1 references POOL_1 and the same thing with number 2
application_profile_ref will vary based on the protocol – To align with NSX-T LB:
for HTTP it will reference System-HTTP
for TCP it will reference System-L4-Application
network_profile_ref will also vary based on the protocol – To align with NSX-T LB
for HTTP it will reference System-TCP-Proxy
for TCP it will reference System-TCP-Fast-Path
Complete object
Adding up everything we created before, we end up with this YAML code!
Adding this code to a blueprint that already has a VM Object and a Network Object will let us do a deployment that will look like this!
Hooray!!!!
Some Caveats and Final Thoughts
Currently, the only supported way to update ALB objects using vRA is via Iterative Updating – this means, applying a new YAML code to the deployment
This can be done by changing the blueprint and then updating the deployment, or by using blueprint-requests API to send new YAML code to the deployment
Official documentation (linked above) and the Swagger are your best friends – There are many more options that can be configured based on your business needs!
I wanted to make this post to invite you to the session I’m going to be presenting at VMware Explore 2023 in Las Vegas, Aug 21-24, with my colleague Pontus Rydin!
The title of the session is “Lessons Learned from the Most Complex VMware Aria Automation 7 to 8 Migration to Date”
In this session we will go over an extremely interesting customer scenario with regards to migration, and how we managed to get to the other side successfully. A lot of requirement analysis, thinking outside of the box, developing process, code, testing, and coming up with creative ideas to a problem that seemed impossible.
We are going to be presenting this session twice!
We will be presenting this at the general session, that is going to be August 22th at 1PM
The code for this session is CEIB1318LV and you can find it in the content catalog!
It’s been a while since I wrote my last post. Many many things happened both in my life as well as work. Not an excuse for my lack of posting, but I do plan to get back to blogging more consistently in the year 2023.
What do we have here today?
In today’s edition, I bring you I script I wrote to move T1 gateways across Edge Clusters in NSX-T. It can programmatically move hundreds of T1s in a couple minutes.
Why would I need to move my T1 Gateways across Edge Clusters?
There are multiple scenarios that would trigger the need to move / evacuate T1 gateways to a different Edge Cluster. The most common are:
During a NSX-V to NSX-T migration, Migration Coordinator will, by default, put all T1 gateways in the same Edge Cluster that is being used for the T0s. In an architecture where there is a dedicated Edge Cluster for T0 ECMP / Uplink, and Edge Cluster/s used for T1 Stateful services (such as load balancing) this is not ideal.
A 10-node XL Edge Cluster can only host up to 400 Small load balancers. Going over this limit will require to build an additional Edge Cluster. vRA can only deploy Load Balancers to a single Edge Cluster at any given time per any given Network Profile. If we reach the limit, we either create the new cluster and change the network profile to the new cluster, or, we can migrate the current T1s to the new cluster, and keep using the one we previously had in the network profile
Rebalancing of T1 Gateways across Edge Cluster for maintain a similar number of T1s across all edge clusters.
How do I use this script?
In the initial comments of the script there is an explanation of the usage
<################################################
Move (T1s) across edge clusters
Author: @ldelorenzi - Jan 23
Usage:
moveT1s.ps1 -nsxUrl <NSX Manager URL (with HTTPS)) -sourceClusterName <Edge Cluster Name> -destinationClusterName <Edge Cluster Name> -execute <$true/$false> -count <count of load balancers to move>
Credentials will be asked at the beginning of the run
################################################>
To dive a little bit deeper into these parameters:
nsxUrl: The NSX-T manager we will be hitting with this script. Including HTTPS
sourceClusterName: The name of the Edge Cluster that hosts the T1 Gateways we want to move
destinationClusterName: The name of the Edge Cluster that will receive the T1 Gateways from the source cluster
execute: By default, the execute flag is set to false. This means that if no value is used in the script, it will default to false. If execute is false, the script will only show us what T1s were found in the source cluster and therefore will be moved to the destination cluster
count: If you don’t want to fully evacuate the cluster and you want to just move some T1s from source cluster to destination cluster, you can set a value for the count parameter and that will limit the amount of T1s that are moved.
Interesting things about the Script
If you look at the code you will see that I built my own wrapper for invoke-RestMethod called restCall – this function has logging included as well as retries. If you’re going to have a lot of REST API calls in your scripts, it could make sense to include something like this!
The ‘movement’ of T1 Gateways actually involves patching the T1 SR object with its new cluster ID. The script finds the Edge Cluster IDs using the names provided at the beginning of the run. This makes it friendlier for users / admins since just the name can be used instead of having to find the id.
Closing Note
I hope you enjoy this post and make use of this script in your environments. If you liked this, please share it!
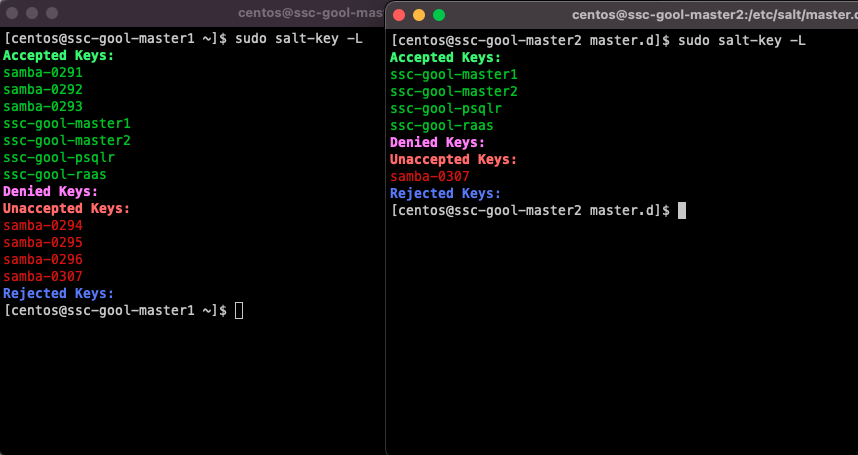
Hello Everyone! On today’s post, I’m going to do a step by step walkthrough of a SaltStack Config (from now on, SSC) enterprise install. The SSC enterprise install is meant to be used in production-grade environments, and can handle up to 5000 Salt Minions per master!
I will also cover how scale-out the deployment and add a new Salt Master (in a cluster configuration) to the deployment after it is finished.
In addition to this, I will cover how to configure a Git repo as a shared storage across masters.
Lastly, I will cover how to prepare a vRA Cloud Template to install the Salt Minion, configure it to use multiple masters, and run a Salt State on the deployment!
Let’s start! Buckle up!
Architecture
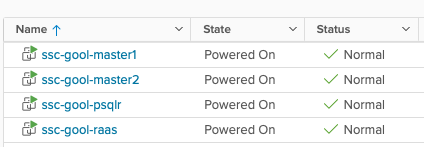
This deployment is going to have:
One VM for PostgreSQL and Redis – Required for persistent & in-memory database components. These two components could be also separated across two different VMs (and configured in HA, but only for manual failover).
One VM for RaaS (Responder as a Service) – This is going to be the GUI of SSC. The RaaS component can also be deployed in a cluster mode using an external load balancer, but I’m going to use a single one in this post.
Two VMs, one for each Salt Master, that will form a cluster. The secondary master and the cluster will be generated after the initial deployment.
Both Salt Masters will be configured to use a Github repository.
All VMs are running Centos 7 as the operating system.
Architecture
This is what my servers look like, from a vSphere point of view.
VMs
List of Steps
What do you need to do to carry out this deployment?
The first list of steps is based on this LINK, which is the ‘Installing and Configuring Saltstack Config’ Official Documentation from VMware.
Prepare the template for the VMs (you can prepare each VM separately but there are common items across all VMs)
Deploy the 4 VMs (take note of the IP addresses)
Prepare the VM that will become the Primary Salt Master
Prepare the VMs that will only be Salt Minions (the PostgreSQL / Redis & the RaaS)
Download & Copy the SSC installer to the Primary Master
Copy and edit the top state files
Edit the SSC settings Pillar file
Apply the highstates to the nodes
Install the License Key
Install and configure the Master Plugin on the Primary Salt Master
Log in for the first time and change the default credentials
Accept the Primary Salt Master key
Optional: Configure Backup for files (if not using a complete backup solution), Set up custom SSL certificates, SSO. (won’t be doing this as a part of this post) -> Link1, Link2, Link3
At this point, you’re going to have a functional SSC enterprise install, but you will only have a single master node. You still need to configure the Secondary Master, the cluster, and the repository!
The second list of steps is based on multiple sources and testing, since there isn’t a single source of information to configure all of this. Which is why I’m attempting to write this and condense it! I will be adding links throughout the steps.
Prepare the VM that will become the Secondary Salt Master
Copy the SSC installer to the Secondary Master
Prepare all the other minions to use Primary and Secondary Salt Masters
Copy Primary master key to the Secondary Master
Edit the RaaS configuration file (master plugin) on the primary master to add the Cluster ID
Install and configure the Master Plugin in the Secondary Master
Edit the RaaS configuration file (master plugin) on the Secondary Master to add the Cluster ID
Start Salt-Master on the Secondary Master and accept the Secondary Salt Master key
Install GitPython on both Salt Masters
Configure the GitFS filesystem and Github repository
Configure a Cloud Template on vRA to install the Salt Minion and configure the two masters
Create a Job using the Salt State hosted in Github
Run the Job!
Don’t be scared! I will be explaining every single step so you’re also able to have a successful deployment. Let’s start!
1: Prepare the template for VMs
You need to install OpenSSL, EPEL, and two libraries for Python (cryptography and OpenSSL) so this is what you need to run:
Create a master.conffile in the /etc/salt/minion.ddirectory and add the following text to configure the minion to use itself as a Master.
master: localhost
Create a the minion_id file in the /etc/salt/ with a descriptive name for the minion using vi, in this scenario, for example, my Primary Master’s minion_id is ssc-gool-master1. This will be autogenerated based on hostname on the first run of the salt-minion service if its not set previously.
Create a master.conffile in the /etc/salt/minion.ddirectory and add the following text to configure the minion to use the Primary Salt Master as its Master
master: IP_OF_MASTER
Set the minion_id (located in /etc/salt) to a descriptive name using vi, in this scenario, for example, my RaaS minion_id is ssc-gool-raas.
Copy the installer to a folder within the Primary Master (it can be the root directory as well), for example, /ssc-installer, and assuming our file is called ssc_installer.tar.gz.
The top state files will be used by the orchestration to install the RaaS, Redis and PostgreSQL nodes.
At this point, you should take note of the Minion ID and the IP addresses of your three nodes, since you will be using them in the following steps. In my case, this is the information:
MINION ID: IP ADDRESS
ssc-gool-master1: 10.0.0.2
ssc-gool-psqlr: 10.0.0.3
ssc-gool-raas: 10.0.0.4
Now, you need to copy and edit the orchestration configuration files.
Important: The instructions below assume that this is a ‘greenfield’ Salt installation. If this is not the case, you might need to edit the following commands to work within your directory/folder structure.
Navigate into the sse-installerfolder (this is the folder that was extracted from the tar.gz file) and run the following commands:
In the /srv/pillar directory, you now have a file named top.sls. Edit this file to define the list of Minion IDs (not IP addresses) that you recorded previously. This is how it looks in my environment
Since as mentioned earlier, my 3 Minion IDs are ssc-gool-master1, ssc-gool-psqlr and ssc-gool-raas.
Also make sure that in the /srv/salt directory you also have a file named top.sls that looks like this:
base:
{# Target SSE Servers, according to Pillar data #}
# SSE PostgreSQL Server
'I@sse_pg_server:{{ grains.id }}':
- sse.eapi_database
# SSE Redis Server
'I@sse_redis_server:{{ grains.id }}':
- sse.eapi_cache
# SSE eAPI Servers
'I@sse_eapi_servers:{{ grains.id }}':
- sse.eapi_service
# SSE Salt Masters
'I@sse_salt_masters:{{ grains.id }}':
- sse.eapi_plugin
7: Edit the SSC settings pillar file
You need to edit four different sections in the SSC settings pillar file to provide the values that are appropriate for the environment. These settings will be used by the configuration state files to deploy and manage your SSC deployment.
Navigate to the /srv/pillar/ssedirectory and edit the sse_settings.yamlfile.
Section #1: Change the values of the four variables to match your Minion IDs. In my case, this looks like this:
# Section 1: Define servers in the SSE deployment by minion id
servers:
# PostgreSQL Server (Single value)
pg_server: ssc-gool-psqlr
# Redis Server (Single value)
redis_server: ssc-gool-psqlr
# SaltStack Enterprise Servers (List one or more)
eapi_servers:
- ssc-gool-raas
# Salt Masters (List one or more)
salt_masters:
- ssc-gool-master1
Section #2: Edit thefollowing variables
pg_endpoint: use the IP address (or DNS name) of the PostgreSQL server. In my environment, this is 10.0.0.3.
pg_port: Port for PostgreSQL. In my environment, I left the default values
pg_usernameand pg_password: Credentials for the user that RaaS will use to authenticate to PostgreSQL
This section looks like this:
# Section 2: Define PostgreSQL settings
pg:
# Set the PostgreSQL endpoint and port
# (defines how SaltStack Enterprise services will connect to PostgreSQL)
pg_endpoint: 10.0.0.3
pg_port: 5432
# Set the PostgreSQL Username and Password for SSE
pg_username: salteapi
pg_password: VMware1
Section #3: Repeat the previous steps but this time, to match your Redis parameters. Since we’re using the same server for both PostgreSQL and Redis, the IP will be the same.
# Section 3: Define Redis settings
redis:
# Set the Redis endpoint and port
# (defines how SaltStack Enterprise services will connect to Redis)
redis_endpoint: 10.0.0.3
redis_port: 6379
# Set the Redis Username and Password for SSE
redis_username: saltredis
redis_password: VMware1
Section #4: Edit the variables that are related to the RaaS node
Since this is a fresh installation, do not change the eapi_usernameand eapi_passwordvalues. You will change the default password at a later step
eapi_endpoint: set it to match the IP address of your RaaS node. In my environment, this is 10.0.0.4
eapi_ssl_enabled: default is set to true. SSL validation is not required by the installer but it will be likely a security requirement in environments that use CA certificates.
eapi_ssl_validation: default is set to false. This means that the installer will not validate the SSL certificate.
eapi_standalone: default is set to false. This variable would be true in the case of the LCM install, in which all components are shared in a single node.
eapi_failover_master: default is set to false. This would be used if you were to configure a Multi Master configuration in failover mode (not active-active) and from within the installer. This will keep its default value since the scaling out will be done afterwards.
cluster_id: This variable defines the ID for a set of Salt masters when configured in a multi-master configuration. The default value should be left here, this will be edited at a later step, once the deployment is already running.
This is what my file looks like:
# Section 4: eAPI Server settings
eapi:
# Set the credentials for the SaltStack Enterprise service
# - The default for the username is "root"
# and the default for the password is "salt"
# - You will want to change this after a successful deployment
eapi_username: root
eapi_password: salt
# Set the endpoint for the SaltStack Enterprise service
eapi_endpoint: 10.0.0.4
# Set if SaltStack Enterprise will use SSL encrypted communicaiton (HTTPS)
eapi_ssl_enabled: True
# Set if SaltStack Enterprise will use SSL validation (verified certificate)
eapi_ssl_validation: False
# Set if SaltStack Enterprise (PostgreSQL, eAPI Servers, and Salt Masters)
# will all be deployed on a single "standalone" host
eapi_standalone: False
# Set if SaltStack Enterprise will regard multiple masters as "active" or "failover"
# - No impact to a single master configuration
# - "active" (set below as False) means that all minions connect to each master (recommended)
# - "failover" (set below as True) means that each minion connects to one master at a time
eapi_failover_master: False
There is also a Section #5, but none of the values need to be edited at this step. These are the customer_idvariable, which is a variable that uniquely identifies a SSC deployment, and the cluster_idvariable, which will be edited once the deployment is already running and the scale-out is done.
8: Apply the highstates to the nodes
At this point, it would be wise to take snapshots of all your nodes, in case something goes wrong with applying the highstates, instead of having to troubleshoot a failed installation, it might be easier to rollback to the snapshot state and start over from this point.
Having said that, to apply the highstates, you need to do the following:
Accept the keys on your Primary Master, you can do that by running the command sudo salt-key -A which will accept all unaccepted keys (at this point, 3)
On your Salt Master, sync your grains to confirm that the Salt Master has the grain data needed for each minion. Since this is a fresh install, you can just run the command to target all the minions, which at this point are just 3.
sudo salt \* saltutil.refresh_grains
Then, run the following command to refresh the pillar data on all the minions
sudo salt \* saltutil.refresh_pillar
Lastly, run the following command to confirm the return data for your pillar is correct
sudo salt \* pillar.items
Confirm that the minions have received the pillar data that you edited on the sse_settings.yaml file, such as IP addresses, Minion IDs, etc
Now that you confirmed the data, it is time to apply the highstates to each node, by running the following command: sudo salt MINION_ID state.highstate – The PostgreSQL database should always be applied first
Which in my environment would look like:
sudo salt ssc-gool-psqlr state.highstate
sudo salt ssc-gool-raas state.highstate
sudo salt ssc-gool-master1 state.highstate
Confirm that the result of applying the highstates is succesful.
Note: you might get a ‘Authentication Error Occurred’ when applying the highstate to the Salt Master. This is expected, and it is deplayed because the Salt Master has not authenticated to the RaaS node yet. This will be solved at a later step.
If this has been successful, you now have a functioning install of SSC. But you still need steps to complete, let’s continue!
9: Install the License Key
To install the License key
Get your License Key from My VMware / Customer Connect (a vRA license is used)
Create a file with a filename ending in _licensesuch as ssc_licensefor example
Edit the file and add your license key number.
Change ownership of the license file and copy the file to the /etc/raasdirectory
Restart the RaaS service: sudo systemctl restart raas
10: Install and configure the Salt Master Plugin
The Salt Master plugin allows the Salt Masters to communicate with SSC. The master plugin is installed on every Salt Master in your environment that communicates with SSC. At this step, you will only install it on the primary Salt Master
Log in to your Salt Master
The master plugin is located in the sse-installer/salt/sse/eapi_plugin/filesdirectory. cd into that directory.
Install the Master Plugin by manually installing the Python wheel, using the following command, and replacing the exact name of the wheel file.
Note: I had to do this step while being logged in as the root user since I was not able to generate the file even with a sudoer user. If this is your case, just switching to the root user and running the command will do the trick.
Edit the generated raas.conffile and update it to use your RaaS server
sseapi_server: Since you enabled SSL at a previous step, the URL should be https://IP_ADDRESS_OF_RAAS – in my environment, it would be 10.0.0.4
sseapi_ssl_validate_cert: However, since you’re not using a CA-signed cert, you should disable the validation to allow for the communication between the Master Plugin and RaaS
This file has more parameters that can be edited at this stage, for example, to set a custom certificate, or specific performance configurations. For more information, visit: LINK
Restart the Master Service: sudo systemctl restart salt-master
You can also check and edit the RaaS configuration file to edit RaaS related parameters. I won’t be covering them in this post and will be using the default values, but more information can be found at: LINK
11: Log in and change the default credentials
Log in to the SSC interface with the default credentials
Then go to Administration -> Authentication -> Local Users, and change the password for the root user
12: Accept the Salt Master Key
Go to Administration -> Master keys. You will see your Master node with a Key in the ‘pending’ state. Accept it.
At this point, you should see your minions pop up in the ‘Minions’ screen.
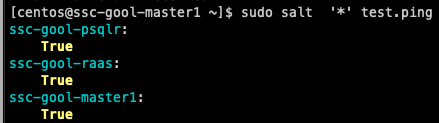
You can then run a simple command, such as test.ping to make sure that you can connect to your minions. For example:
Testing ping command from salt.master
You can also test this from the RaaS console, by selecting the minions and running the same job
Running test.ping job from the console
Congrats, if you made it here, you have a functioning distributed install of SSC! Now you will scale this out to allow for multiple masters and a shared repository!
A little break
At this point, we have configured our initial deployment. From now on, I will cover how to scale this out to add a secondary master, and configure a git repository!
14: Prepare the VM that will become the Secondary Salt Master
Follow Step #3 from the list, but this time using the Secondary Master VM!
15: Copy the SSC installer to the Secondary Master
Follow Step #5 from the list, but only copy the file, since you already downloaded it in that step.
16: Prepare all minions to use both masters
At this step, you need to edit the /etc/salt/minion.din all the minions to use both masters. In the case of the nodes that are masters, you can just keep the localhost value and add the value of the secondary master to each node. In the case of the nodes that are minions (PostgreSQL/Redis, RaaS) you can append the IP of the secondary master to the file. Keep in mind that this will now become a list, and the syntax changes. The files should look like this (using the IPs from my environment)
Restart the Salt Minion service on each node after editing the files: sudo systemctl restart salt-minion
17: Copy the Primary Master Key to the secondary master node
This is a requirement to be able to use a redundant master (regardless of it being configured in an active-active configuration or active-passive). The masters need to share the private and public key.
You should log in to the Primary Master and run the following commands to copy the files. This can be done with the root user if you run into any issue with accessing the folder. Overwrite the existing files if prompted.
cd /etc/salt/pki/master
scp master.pem USERNAME@IP_OF_SECONDARY_MASTER:/etc/salt/pki/master/
scp master.pub USERNAME@IP_OF_SECONDARY_MASTER:/etc/salt/pki/master/
Then, log in to the Secondary Master and restart the Master Service: sudo systemctl restart salt-master
18: Edit the RaaS configuration file (Master Plugin) on the primary master to add the Cluster ID
Since we’re going to place both masters in the same cluster, we need to make RaaS aware of this. This configuration is handled in the Master Plugin configuration.
To do this change, open the /etc/salt/master.d/raas.conffile on the Primary Master and edit the value of the sseapi_cluster_idvariable. In my environment, this looks like this:
sseapi_cluster_id: goolcluster # SSE cluster ID for this master (optional)
As we saw on the Architecture image, my cluster will be called goolcluster
Then, restart the Salt Master service on the Primary Master: sudo systemctl restart salt-master
19: Install and configure the Master Plugin in the Secondary Master
Follow Step #10 using the Secondary Master VM.
20: Edit the RaaS configuration file (Master Plugin) on the secondary master to add the Cluster ID
Follow Step #18 using the Secondary Master. Make sure to use the same Cluster ID, in this case, goolcluster.
21: Start Salt-Master on the secondary master and accept the second Salt Master Key
Log in to the Secondary Master, then run the following command to start the Salt Master service: sudo systemctl start salt-master
Then, log in to SSC using a browser, and accept the Master Key for the secondary master. Once it is accepted, it should look like this:
Both master keys accepted
At this point, since all minions are configured to use both masters, you will get pending minion keys in the SSC console. You can accept them there.
Note: Since both masters are part of the same cluster, SSC will recognize them as the same node. They will show up in the ‘Pending’view of keys, but they will show up as already accepted. You need to accept them again (since this will be accepting the key in the secondary master). In the future, new minions will only need to be accepted once, since accepting on SSC will run the job to accept keys on both Salt Masters
The next steps will be about configuring the GitFS filesystem, which is one of the ways you can use a shared filesystem for both masters. It is a requirement to have a shared filesystem across masters, otherwise you could have inconsistent information depending on what master is being used for any given Job instance.
22: Install GitPython on both Salt Masters
Configuring a GitFS filesystem in a Salt Master can be accomplished through two methods:
Via GitPython
Via pygit2
I was having trouble with pygit2 in CentOS and getting Salt to recognize the version (this has been reported in multiple Git and Stackoverflow posts), so I ended up using GitPython instead, and this is what I will be describing.
To install GitPython, and its dependencies (such as the git cli), log in to both Salt Masters and run the following command: sudo pip3 install GitPython
After installing it, make sure that it shows up as being used by Salt. Salt uses its own Python version so some packages don’t always get recognized.
Run the following command: salt -V
[centos@ssc-gool-master2 ~]$ salt -V
Salt Version:
Salt: 3004.1
Dependency Versions:
cffi: 1.9.1
cherrypy: Not Installed
dateutil: Not Installed
docker-py: Not Installed
gitdb: 4.0.9
gitpython: 3.1.20
Jinja2: 2.11.1
libgit2: Not Installed
M2Crypto: 0.35.2
Mako: Not Installed
msgpack: 0.6.2
msgpack-pure: Not Installed
mysql-python: Not Installed
pycparser: 2.14
pycrypto: Not Installed
pycryptodome: 3.14.1
pygit2: Not Installed
Python: 3.6.8 (default, Nov 16 2020, 16:55:22)
python-gnupg: Not Installed
PyYAML: 3.13
PyZMQ: 17.0.0
smmap: 5.0.0
timelib: Not Installed
Tornado: 4.5.3
ZMQ: 4.1.4
Salt Extensions:
SSEAPE: 8.6.2.11
You can see that GitPython shows up as installed and with version 3.1.20, while pygit2 is not installed.
23: Configure the GitFS filesystem and Github Repository
The URL for the repository that I’m using now is public, and it is https://github.com/luchodelorenzi/saltstack -> you can use it as well for doing the same tests I will be doing on this deployment.
All the steps of this configuration need to be done on both Salt Masters, since they’re now running in a cluster
Edit the fileserver_backend parameter and add the ‘gitfs’ filesystem to the /etc/salt/master.d/raas.conffile.
Create a new file in the same directory, called gitfs.confand add the following parameters
gitfs_provider: gitpython
gitfs_update_interval: 60
gitfs_base: main
gitfs_remotes:
- https://github.com/luchodelorenzi/saltstack.git
Note: the same raas.conf file could have been used to append the gitfs parameters. However, Salt will look for all *.conf files in the master.ddirectory, so separating this in a different file could make it easier to maintain / check.
What do each of the parameters mean?
gitfs_provider: The provider that will be used to leverage GitFS. In this case, GitPython
gitfs_update_interval: Update interval for gitfs remotes.
gitfs_base: Defines what branch or tag is used as the base environment. The main branch on my repository is main, but it can change depending on yours
gitfs_remotes: List of the repositories. Only adding one in this deployment. You can have multiple deployments, and some parameters are overridable per remote.
There are multiple other parameters for GitFS. For more information please follow this LINK on the GitFS section. You can also follow this other LINK for a GitFS walkthrough.
After configuring this, restart the Salt Master on both nodes, by running the following command: sudo systemctl restart salt-master
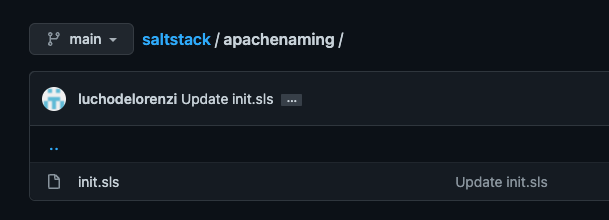
Now, you need to check if our files are being read from Github! Since the mapping was done to the base environment, running the following command will show every state file in that environment. For example:
The apachenaming state resides on Github, as you can see here:
Github Repository
So hooray, we can now use this Salt state from Github, and this is shared across both masters, has version control, you can use multiple repos, multiple branches. Pretty cool, isn’t it?
24: Configure a Cloud Template to Install the Salt Minion and Configure Two Masters
Since the vRA integration with SSC does not allow to integrate with Multiple Masters, I will use CloudConfig to perform the initial installation and configuration. As a prerequisite for this, your template should be prepared to use CloudConfig
This is the CloudConfig Code in the Template I’m using:
Run it to install the Salt Minion and point it to one of the masters
Change ownership of the minion.ddirectory to the ubuntu user which is the user that’s being used by CloudConfig in this template
Remove the 99-master-address.confthat was generated during the Salt Minion install
Create a new file with the addresses of the two Salt Masters (and using the correct list syntax)
Restart the salt-minionservice
After doing this, if I do a deployment, the minion will show up in both masters with a Pending state. Let’s go ahead and deploy a server!
This is the result of the deployment
If I go to the SSC console, I will see this Minion pop up under the pending keys
And you can see that this will come up as pending on both masters! This means that the changes on the master.conffile on this instance of the deployment worked.
samba-0307 is pending on both masters
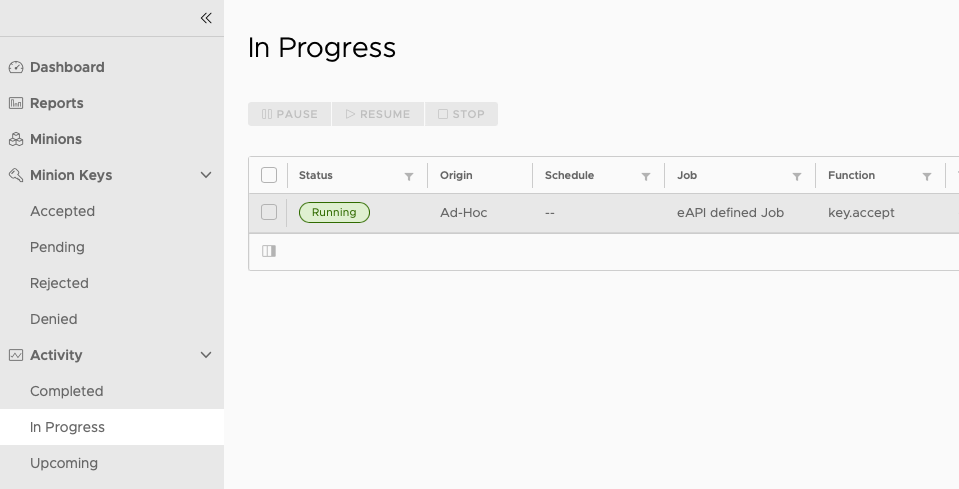
Now, if you accept the key on the SSC console, it will be accepted on both nodes. Accepting the key triggers a job that you can see on the Activity view.
Once the action is completed, the key will be accepted on both Masters, so both Masters wil be able to interact with the minion. This is a brief excerpt from the output of the job run
You can see that the action was executed on both masters, since they’re both part of a cluster.
25: Create a Job using the Salt State hosted in Github
The second to last step of this post. You will now create a job and use the Salt State located in the Github Repository.
Go to Config -> Jobs and click on Create Job
Under Command, select salt
Do not select any targets
Under Function select state.apply
Do not select an environment
Under states type in the name of the state, which is the name of the folder in Github. In this case, it will be apachenaming
Click on Save
Note: The SSC console does not have access to the GitFS filesystem, therefore, a State that exists in Github will never show up in the drop down list of States when the Job is being created. This is expected behavior, and why wou need to type the Salt state name.
26: Run the Job!
You made it! This is the last step! You will now test that you can actually run a job with a State file hosted on Git!
Go to ‘Minions’, select the minion that was deployed, click on Run Job and select the apachenaming job, and then click on ‘Run Now’
This job will install Apache on the server, and then configure the welcome page to show my name (LuchoDelorenzi) on it! This is the code of the state file (this is public on Github)
And after the Job is completed, this is the result!
FINISHED!
If you made it this far, congratulations! I know this has been a really long post full with information, but I hope that you found it simple enough to consume and be able to attempt this deployment (and tweak things for your environment) based on this post!
Closing Note
As usual, looking forward to feedback in the comments. And if you liked the post, please share it! The more people I can help, the better!
Hello Everyone! I hope you’re having a good end of the year.
On today’s post, I will talk about a specific use case and one of the ways to solve it:
The business need was to do the following:
Have a single master template with dozens of inputs, to fullfill every deployment need.
This master template will be consumed by multiple projects and different users
Availability of inputs need to change based on the consumer / project
Visibility of inputs needs to change based on the consumer / project
Format of inputs needs to change based on the consumer / project
Source (in case of external data) for input data needs to change based on the consumer / project
You can see that we’re hitting a few limitations in the vRA OOB code:
The ‘conditional’ values for existence, visibility, format, etc, for a service broker form inputs don’t allow for this level of customization
A single cloud template can’t have more than one service broker form attached to it
So how do we solve this business need? Here comes the API solution!
Important: all the API information in swagger format (everything that was used in making this solution) is available in your vRA instance at https://VRA_FQDN/automation-ui/api-docs
API Documentation URL
What does the solution need to accomplish?
I will make a quick summary of what the code needs to do
Grab the inputs from a service broker form (and the requester ID, this is important)
Save the actual deployment name, but make the API deployment (mapped to the vRO workflow) use a temporary
Use the inputs to deploy the master template blueprint via the API (since we’re using the API and we don’t have access to the requester’s credentials, the API call will be executed by an administrative account configured in vRO)
Poll the master template blueprint deployment until it is successful
Once it is successful, change the owner to the original requester
Once that is done, destroy the temporary deployment that generates the API one.
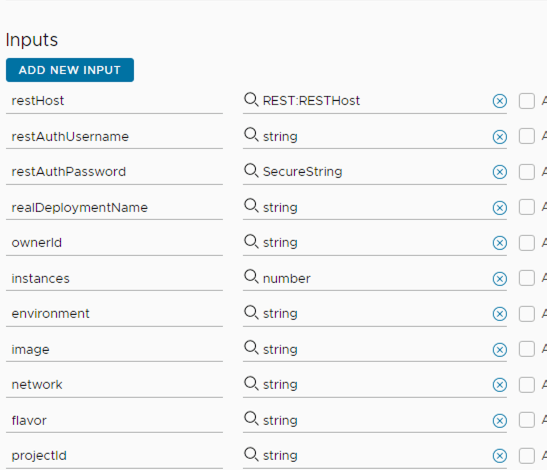
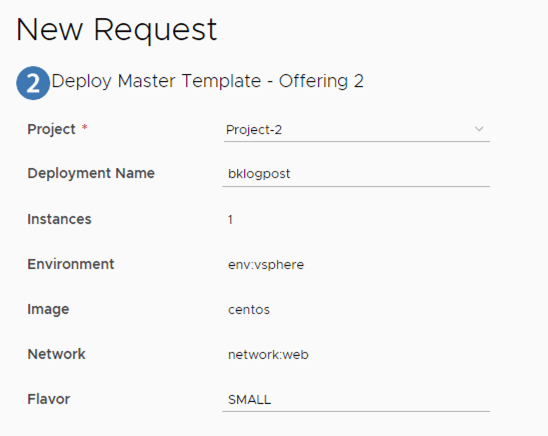
These inputs (and a bit more) are the ones that are going to be used in the API call to the blueprint-request API -> part of that code. I create the body of the call with the inputs
Now those inputs need to be part of the action and the workflow we’re going to use, as you can see here:
vRO Action Inputs
You can see that we have some extra inputs that are not in the blueprint!
All the REST configuration will be variables of the workflow that is calling the action. This will use the previously configured REST host and the credentials
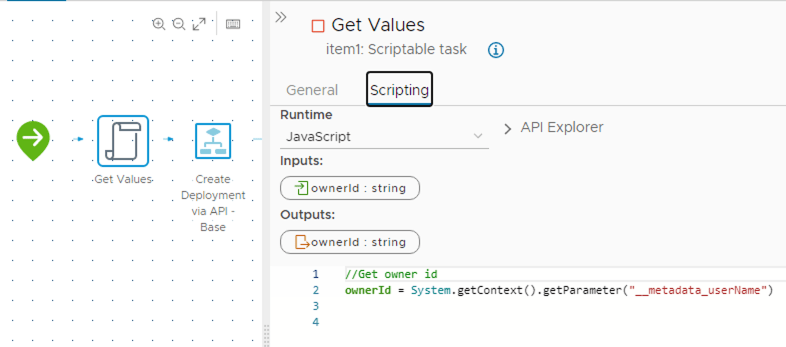
ProjectId is needed for the deployment, and we get that from the Service Broker Form
ownerId is needed for the deployment change owner action, and we get that from the execution context of the workflow that is being called by the service broker form
realDeploymentName is the actual deployment name (remember that the Service Broker form will use the temporary deployment name, and the actual deployment will use the name you input.
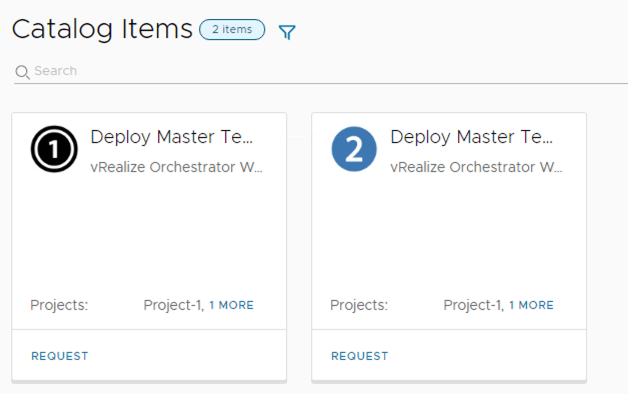
So what does the structure look like? In this case, we have two offerings for two projects:
Each of them have different configurations for the fields, for example:
projectId and temporary deployment name are visible fields, the rest is editableprojectId and temporary deployment name are not visible, plus, a bunch of fields aren’t editable
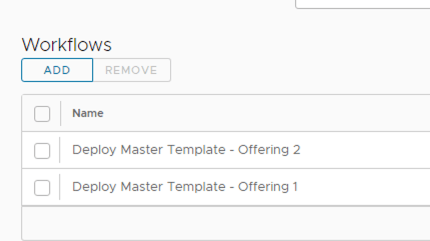
These two service broker forms map to two vRO workflows:
The two workflows
Why do I need two workflows? because as mentioned before, I can’t use two service broker forms for the same catalog item. However, these two vRO workflows are just wrappers of the ‘main’ workflow
The ‘offering’ workflow is just a wrapper for the base workflow
However, there is an important caveat here. The ownerId will only be part of the workflow that is called by Service Broker, in this case, the wrapper one. So the information for the requester is on the execution context of this workflow.
And I need to pass that to the base workflow. So how do I do that? By extracting the property from the execution context, and then passing it to the base workflow.
The only thing left now is to destroy the temporary deployment after it is done with the API one. So how do we do that?
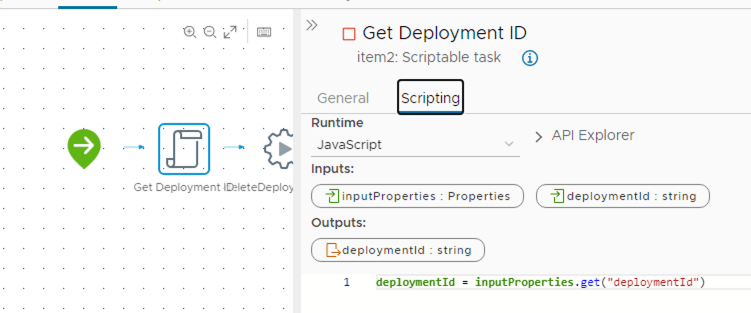
We have a workflow that will delete a deployment via API – It basically calls the the deployments API with a DELETE action
//delete Deployment
System.log(deploymentId)
var request = restHost.createRequest("DELETE", "/deployment/api/deployments/"+deploymentId);
request.contentType = "application/json";
request.setHeader("accept", "application/json");
request.setHeader("Authorization", "Bearer " + tokenResponse)
//Attempt to execute the REST request
try {
response = request.execute();
jsonObject = JSON.parse(response.contentAsString);
System.log(response.contentAsString)
}
catch (e) {
throw "There was an error executing the REST call:" + e;
}
The deploymentId comes from the subscription run. Since this is run from the Event Broker state ‘Deployment Completed’, we have the deploymentId available there
deploymentId parameter on the event broker state
So we just extract it (the same way we did with the execution context) but from the inputProperties (payload used in the event broker subscriptions)
So how does all of this look in an actual run? Let’s show it in a video! (takes around 6 minutes, you will see the temporary deployment being generated, then the actual one via the API, the owner name change, and the destruction of the original one.
Deployment DEMO!!!
And I’m going to attach the code of the two most important actions that form the workflows (deployViaApi and deleteDeployment) here:
I hope you enjoyed reading and understanding this as much as I did while trying to come up with this solution and then making this a reality. This idea can be heavily customized to suit other use cases (and grow this one way more) but the principles used here should still apply!
Please leave your feedback in the comments if you liked it, and share it!
On today’s post, we will dive into a practical example to use vRealize Orchestrator Configuration Elements to help with a business need for vRA 8 Custom Forms!
The Problem
Customer X is using a single cloud template with multiple inputs backed by vRO Actions. The main input, and what defines pretty much all the rest, is the project selected. Given the complexity of the inputs, the cloud template can be used by all projects and by many different use cases.
Customer X was trying to improve the form loading times, which were around 10 seconds for the initial loading, plus 10 more seconds every time they changed the project in the form. This heavily impacted the user experience since it was giving a sensation of ‘slowness’ overall to anyone that was requesting the items.
The project defines, for example (there are more fields, but these are the ones we will use as example):
Hostname prefixes
Puppet roles
AD OUs
Portgroups
vCenter Folders
Each project has a ‘Project Map’ which contains different modifiers to then perform a different search in an external API, which has a cache of the objects needed, to reduce the time needed to gather the data (for example, sending API calls to vCenter to get folders)
However, the fact that the Project Map does not have all the information and needs to be processed in real time ends up adding more loading time to the form than desired.
A solution: vRO Configuration Elements
Emphasis on ‘A solution’ and not ‘THE solution’ since there could be other (even better!) ways to solve this problem, but this is how I approached it and will show it in this blog post.
vRO configuration elements, are originally used for example, for sets of variables that will be used in multiple internal actions/workflows, to avoid having the same data in many places, and for ease of managing. The configuration elements can be referenced in workflows or actions and the information is only changed in a single place.
However, there is another use we can give to configuration elements and that is using them as a Database!
All the configuration elements reside in the vRO DB, and the elements used can be of any of the types that exist within vRO.
Creating a Configuration Elements category called ‘Projects’
Create one configuration element per project, within that category. The easiest way to accomplish this is to create one configuration element, define all the needed attributes, and then just duplicate that configuration element to match all the projects you need – In this case, since we need to retun this to vRA Custom Forms, mostly in drop-down form, we will be using string arrays
One configuration element per project, with the variables mentioned
An action that will return the values to the custom forms, using two inputs, the Project we want to get the information from, and the value that we want to get. That makes the action reusable by multiple fields in the form: In this case, I called it getConfigurationElementValue and it can be seen on the following link: https://github.com/luchodelorenzi/scripts/blob/master/getConfigurationElementValue.js
An action or workflow that will:
Get the data from the external API
Populate the configuration elements with that data
This action/workflow can be scheduled to run every minute, every 5 minutes, depending on the need.
The data will be persisted in the vRO DB so that’s why I’m calling this a ‘database’ instead of a cache, however, it could very well be called a ‘persistent cache’ since all it is doing is to make the data available to the user as fast as possible but not doing any processing.
This workflow runs every 5 minutes and updates the values on all the existing projects (Configuration Elements)
The important thing to note here is that there isn’t any processing from the Custom Form to the vRO configuration elements when the user requests a catalog item!. Getting the data directly from the vRO DB without any processing at request time is what is going to give us the fastest loading times. All the processing is done in the background, without none of the requesters noticing!
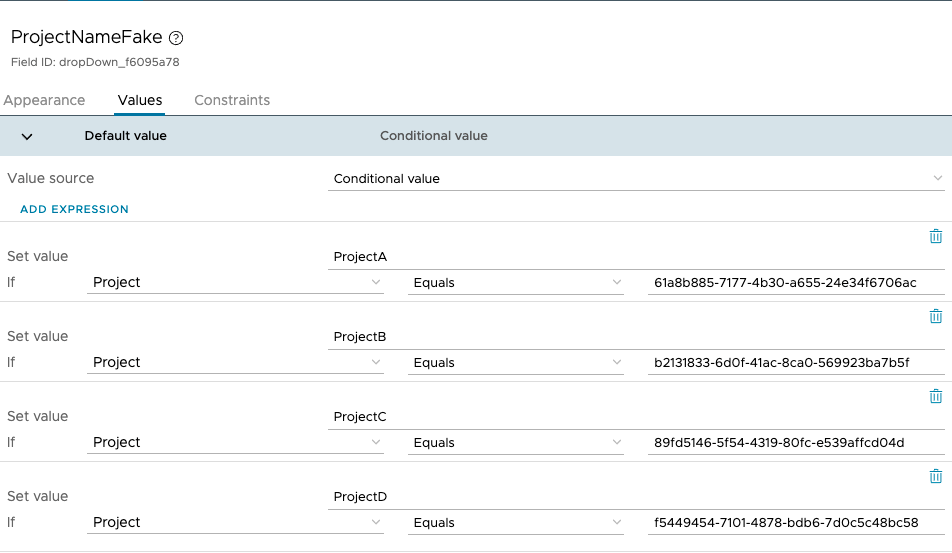
The last step is to refer to the getConfigurationElementValue action in our custom form
A small caveat – the way vRA 8 and the ‘Project’ field works is that even though the project shows the user the names to be chosen, it is actually processing the IDs, so in this case I added a hidden field called ProjectName which is what I will be actually using to convert the IDs to names (since the configuration elements are based on the name)
Mapping the Project IDs to namesUsing the getConfigurationElementValue action to get the values needed in the form
This is a small demo of how this works, take a look at the loading times for the form and changing the project! (And this is on a nested lab!)
Video Demo
Summary
To reiterate, the important things are:
No (or as little processing as possible if there is a field that cannot be used with configuration elements) should be done in the actions that are returning the data to the custom form
All the data should be processed in the background – The requester won’t be aware of it
Adding new projects it is as simple as duplicating one of the existing ones and changing the name. The way the workflows and actions are coded in this example will always look for every project (configuration element) below the ‘Projects’ folder
Getting the data out of the vRO DB directly via configuration elements instead of going to external sources, is the fastest way to get the values in the form.
Closing Note
I hope you found this interesting! It is using configuration elements in a way that might not be the most common usage, but it can bring great benefits to user experience when interacting with vRA requests. Having the data processed in the background and having really short form loading times will give the sensation of having more ‘speed’ to the tool itself!
Feel free to share this or leave a comment if you thought it was interesting!
On today’s post, we will go through creating an ABX Action to change the DNS Servers for a Deployment in vRA8. This might be needed to do in scenarios in which, even though the network has DNS servers configured, a specific deployment might require to use other DNS Servers while still being on the same network, for example, to join a different AD domain
The same idea can be used to edit other fields of the deployment, such as the IP Address, search domains, etc.
The post will be divided in 5 sections:
Cloud Template
Event Topic
ABX Action
ABX Subscription
Test
Cloud Template
In the template we’re going to need two inputs – dnsServers (comma separated list of DNS Servers) as well as an input to manage the amount of VMs in the deployment, we can call it ‘instances’
instances:
type: integer
title: Amount of VMs
default: 1
maximum: 5
dnsServers:
type: string
description: Comma separated list of DNS Servers
title: DNS Servers
default: '1.1.1.1,8.8.8.8'
These two values will be custom properties on the VM Object
In addition to this, the network assignment for the VM resource should be set to ‘static’. A customization specification profile is optional, since using a ‘static’ assignment will auto-generate a ‘ghost’ customization specification profile at the time of provisioning
The event topic that we need to use to make changes to the Network Configuration is the one that has the object that we need to edit being presented to the workflow in an editable state, as in, not read-only.
For this specific use, the state is Network Configure
Pay special attention to the ‘Fired once for a cluster of machines’ part
The dnsServers object is a 3D Array, so that is what we need to use in the ABX Action Code
So from this point we learn that:
The action will run once for a cluster of machines, so if we were to do a Multi-VM deployment we need to take this into account, otherwise, it will only run for a single VM and not all of the VMs in the deployment
a 3D array needs to be used to insert the DNS Servers into the object at the event topic
ABX Action
For this example, I will use Python, and I will not use any external libraries for array management (such as numpy) since I wanted to see if it could be done natively. Python has way better native support for lists than it does for arrays, but in this case, given the schema of the object in the event topic, we’re forced to use a 3D Array.
The first thing we need to do when creating the action, is to add the needed inputs. In this one, I will add the custom properties of the resources as an input
Adding the custom properties
Once we have that as an input, we can use it to get the data we need (amount of instances and DNS servers)
To pass data back to the provisioning state, we will use and return the ‘outputs’ object
This is the code of the action itself, I will explain it below
def handler(context, inputs):
outputs = {}
dnsServers = [[[]]]
instances = inputs["customProperties"]["count"]
inputDnsServers = inputs["customProperties"]["dnsServers"].split(",")
if (len(inputDnsServers) > 0):
outputs["dnsServers"] = dnsServers
outputs["dnsServers"][0][0] = inputDnsServers
for i in range(1,int(instances)):
outputs["dnsServers"] = outputs["dnsServers"] + [[inputDnsServers]]
return outputs
Define the outputs object
Define the 3D Array for DNS Servers
Assign the inputs as variables in the script
Convert the comma separated string into a List
If the list is not empty (this means that the user did enter a value in the DNS Servers list on the input form) then we add the 3D Array to the outputs object.
Why am I asking to see if it is empty? Because if the user did not put anything on the field, we will be overwriting the output with an empty array, and that will overwrite the DNS that were read from the network in vRA. We only want to overwrite that if we’re actually changing the DNS Servers.
Also in the same condition, we want to add the DNS Servers array to each VM, so we iterate through the amount of VMs.
The way to add it without using numpy (we have no append method) is not elegant, but it does the trick. Basically, we initialize the first element and then we add other elements to the same array using the same format.
Return the outputs object
This can also be done in javascript and powershell, the idea would be the same.
So how does this object look like in an actual run?
In this example, I changed the DNS for 3 VMs – You can see that we’re using the 3D Array Structure
Lastly, we need to configure a subscription for it to run at this specific state.
ABX Subscription
This is the most straightforward part – We create a blocking subscription in the Network Configure state, and we add the action we just created
The ABX subscription can be filtered via a condition (for example, to run only on specific cloud templates) as well.
So let’s do our deployment now!
The network i’m going to select has the 8.8.8.8 DNS configured
This will be overwritten by whatever we put on the input form. I’m going to use 1.2.3.4 and 5.6.7.8 for this example, and there will be 2 VMs in the deployment
We can check the output of the action before the deployment finishes
Action run started by an Event (Subscription)Action output
In there we can see the actual code that run, if it was successful or not, the payload, and the output the action had. In this case, our two DNS Servers for our two VMs with a successful output.
Checking the DNS for one of the VMs, we can see the two DNS Servers we selected as inputs!
Success!!!
Summary
I hope you found this post useful! The same idea can be used to change several other properties at provisioning time. Also, it was a learning experience for me to learn how to play with arrays in Python natively, and how to interact with ABX properly.
More posts will be coming soon!
If you liked this one, please share it and/or leave a comment!
On today’s post, I will focus on a Dynamic Multi-NIC configuration for a Cloud Template in vRA 8.x
This allows customers to reuse the same cloud templates for virtual machines that could have a different amount of NICs, and this amount is defined at the time of the request. If this wasn’t dynamic, then a cloud template with three networks, will always need to have three networks configured at the time of the request, which might not be the case.
Using a Dynamic construct allows for less cloud template sprawl, since multiple application configurations can use the same cloud template.
Since this configuration is not trivial, this post will be a step by step guide on how to achieve this result.
Current Environment
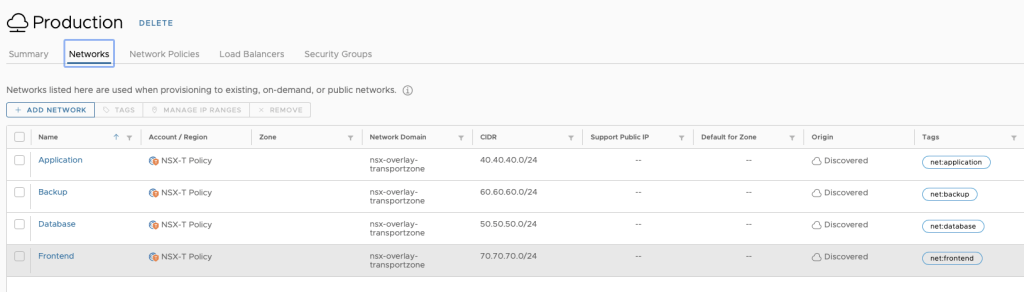
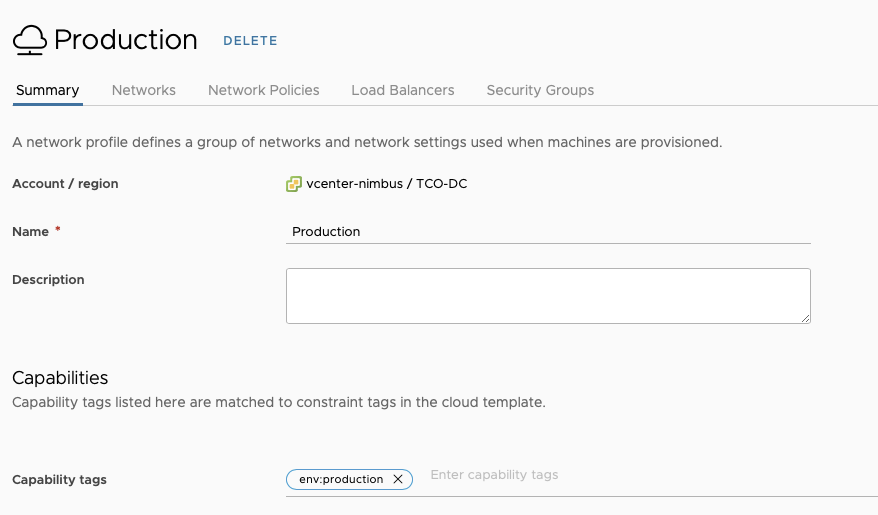
For this Lab demonstration, we will use a vSphere Cloud Account, 4 NSX-T segments that are part of a Network Profile with a capability tag named “env:production” – In doing so, when using that constraint tag in the cloud template, we can guarantee our deployment will use that specific network profile.
The 4 NSX-T segments also have a single tag that refers to the type of network it is. In this scenario, Application, Frontend, Database and Backup are our 4 networks.
NSX-T Segments tagged and defined in the network profile‘env:production’ tag in the network profile
Creating the Cloud Template
To get the Dynamic Multi-NIC configuration on the Cloud Template to work, we need the following things:
Inputs for Network to NIC mapping based on tagging
Inputs for NIC existence
Network Resources
VM Resource and Network Resource assignment
In addition to this, we can do customization in Service Broker to change the visibility of the fields. This is done to only allow the requester to choose a network mapping for a NIC what will actually be used.
Inputs for Network to NIC mapping based on tagging
This cloud template will allow for configurations of up to 4 NICs, and since we have 4 networks, we should let the requester select, for each NIC, what networks can be used.
We can see that each of the inputs allows for any of the networks to be selected.
Inputs for NIC Existence
Other than the first NIC (which should always exist, otherwise our VM(s) wouldn’t have any network connectivity, we want to be able to deploy VMs with 1, 2, 3, and 4 NICs, using the same Cloud Template.
To achieve that, we will create 3 Boolean Inputs that will define if a NIC should be added or not.
To manage the configuration of the NICs and networks, the network resources for NICs 2, 3 and 4 will use a count property, and this property’s result (either 0 if it doesn’t exist, or 1 if it does exist) will be based on the result of the inputs. Network 1 will not use that property
Also, we will use the deviceIndex property to maintain consistency with the numbering – So the network resources look like this
The constraint tags that are used are the Network Input (to choose a network) and the ‘env:production’ tag to make our deployment use the Network Profile we defined earlier.
VM Resource & Network Resource Assignment
This is the tricky part – Since our networks could be non-existent (if the needNic input is not selected) we cannot use the regular syntax to add a network, which would be something like:
This will fail on the Cloud Template validation because the count for Network2 could be zero, so to do the resource assignment, we need to use the map_by syntax.
This allows for any combination of NICs, from 1 to 4, and if the count of one of the resources is 0, it won’t be picked up by the assignment expression.
This is what the Cloud Template looks on the canvas. You can see that Networks 2, 3 and 4 have the appearance of possible multiple instances. This is because we’re using the count parameter.
Canvas view of the Cloud Template
If we were to deploy this Cloud Template, it will look like this:
Doesn’t make much sense to select networks that we won’t assign, right?
How do we fix this? We can leverage Service Broker to manage the visibility of the fields based on the boolean input!
Using the inputs as conditional value for the visibility of the network field
So now, from Service Broker, it looks like this:
No extra NICs selectedNICs 2 and 3 selected
So if we deploy this, it should have three networks assigned. The first NIC should use the Application Network, the second NIC should use the Frontend Network and the 3rd NIC should use the Database Network.
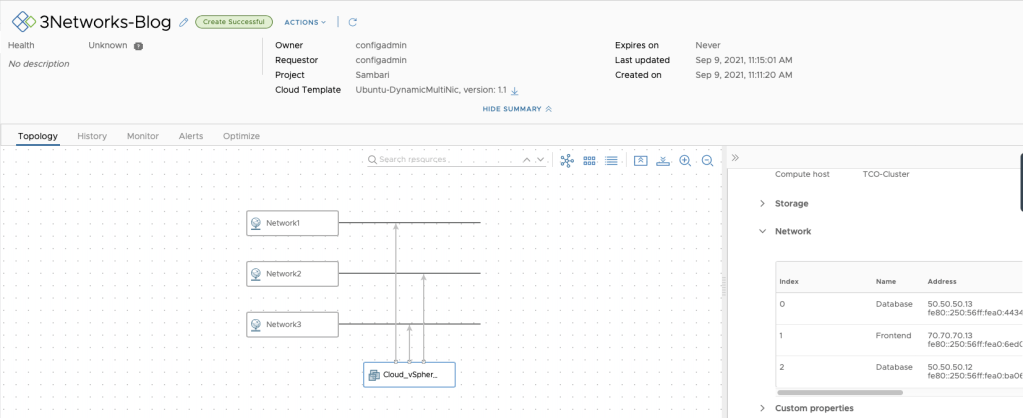
Let’s test it!
TA-DA!
We can see that even if the Cloud Template had 4 Network Resources, only 3 were instantiated for this deployment! And each network was mapped to a specific NSX-T segment, thanks to the constraint tags.
Closing Note
I hope this blog post was useful – The same assignment method can be used for other resources such as Disks or Volumes – the principle is still the same.
Feel free to share this if you found it useful, and leave your feedback in the comments.
On today’s post, we will go through the process of updating an onboarded deployment in vRA 8.x
The onboarding feature allows customers to add VMs that were not deployed from vRA, to the vRA infrastructure. This means that these VMs are added to one or more deployments, and once they exist within vRA, operations such as power cycling, opening a remote console, or resizing CPU/RAM are now available.
However, there are scenarios in which customers would want to expand these deployments, not with new onboarded VMs, but with newly deployed VMs (or other resources) from vRA! These deployments will use an image, a flavor, could use a multitude of inputs, tagging, networks, etc. So how do we do this?
Onboarding the VMs using an auto-generated Cloud Assembly Template
The first thing we need to do, is to create an onboarding plan, select a name for our deployment, and select the VMs we’re going to onboard initially.
Creating the Onboarding PlanAdding two VMs to be onboarded
On the deployments tab, we can rename the deployment if needed, but the most important part is to select Cloud Template Configuration and change it to Create Cloud Template in Cloud Assembly Format– this will allow us to have a source for our deployment, that we can edit afterwards to allow for future growth
Cloud Template in Cloud Assembly format
It is important to note that the imageRef has no image available. Since this is not a vRA Deployment but an Onboarding, none of the resources are being deployed from any of the images. We will come back to this item later.
After saving this configuration and clicking on Run, our deployment will be onboarded
Updating the onboarded deployment to add a new VM in a specific network
If we check on the onboarded deployment, we will see that it is mapped to a specific Cloud Template (the one that was auto-generated earlier by the Onboarding Plan)
So if we were to do an update on this deployment, we need to edit that Cloud Template
I will now add a vSphere Machine resource as well as a vSphere Network:
This is what our template looks like now. So the next thing we should do is click on Update, right?
Update is Greyed out!
The update task is greyed out because ir Cloud Template does not have inputs. Since we don’t have inputs, what we need to do is to go to the Cloud Template, and instead of selecting Create a New Deployment we should select Update an Existing Deployment and then click on the onboarded deployment.
Updating the Onboarded Deployment
After clicking on Next, the plan is presented.
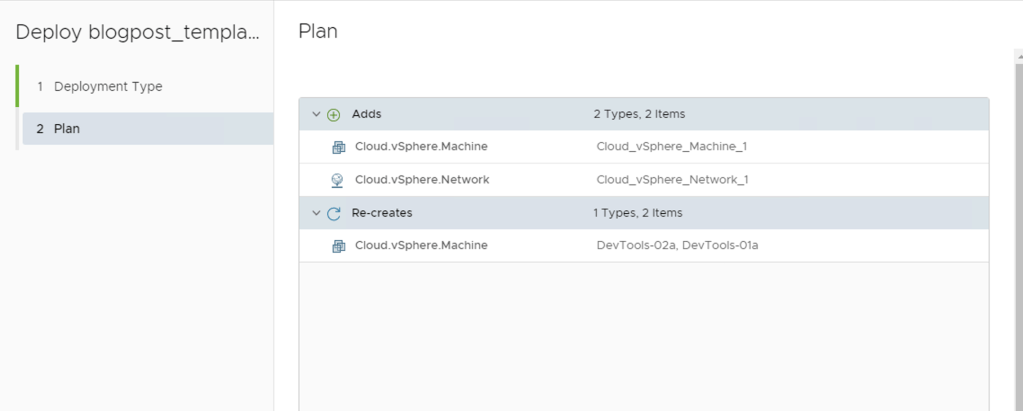
Notice something wrong here?
The update operation will attempt to re-create the onboarded VMs! That’s not something we want, and also, in this scenario, it will fail since there is no image mapping to deploy from!
What we want is to leave all the VMs that were previously onboarded, untouched, and only add our new VM and network. So how do we achieve this?
This is achieved by adding the ignorechanges parameter with a value of true to every resource in the cloud template that was previously onboarded – In this scenario, this would be our 2 DevTools VMs
Adding the ignoreChanges parameter
If we re-try updating the deployment now, the only tasks that should appear will be the ones for the new resources (VM and Network)
Update deployment showing the new tasks
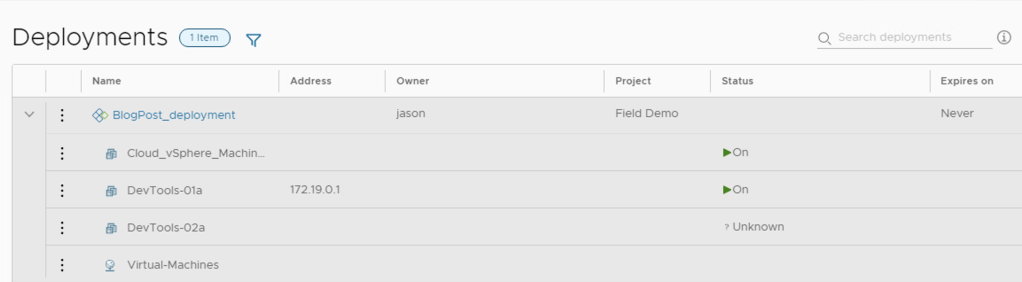
After clicking on ‘deploy’ and waiting for it to finish, our deployment will now like this
Deployment updated with our new VM and network! Hooray!
Offboarding/Unregistering limitations
It is important to note that vRA’s limitations for unregistering VMs are still present. The only VMs that can be unregistered from vRA are the ones that were previously onboarded. VMs that were deployed from vRA will not be able to be unregistered without deletion. The fact that the deployment VMs are part of an Onboarded Deployment does not change this.
Closing Note
I hope you enjoyed this post! When I started working on this use case I figured it was not as trivial as I thought, and after doing research and testing, found this walkthrough/solution.