Hello Everyone!
On today’s post, we’re going to talk about the newly released feature in Aria Automation 8.16.1 which is the native integration with the AVI Load Balancer (also called Advanced Load Balancer, and from now on this post, ALB) by using a NSX-T Load Balancer as an example and starting point.
The goal of this post will be for you to be able to operate with the AVI Load Balancer from Aria Automation in the same way that you can do today with the NSX-T Load Balancer.
Initial Setup
For the initial setup and cloud account configuration, you can follow https://docs.vmware.com/en/VMware-Aria-Automation/8.16/Using-Automation-Assembler/GUID-190DD085-2F1B-4888-A7F1-DAA8D5A8380E.html
On that document, in addition to a list of steps, you will also see what permissions are needed by the Aria Automation user that will be interacting with ALB.
It is important to configure these Cloud Accounts with the same capability tags that the vCenters in the same location (and that will be hosting these resources) have.
While there is a native ‘association’ between NSX-T and vCenter, that concept does not currently exist with ALB. If you plan on having more than one ALB Cloud Account in your Aria Automation instance, and you plan to leverage the allocation helper construct (which we will talk about later) make sure the tagging is in place.
This will create a Cloud Zone in Aria Automation as well. Make sure you are adding this Cloud Zone to the projects you plan to consume (as stated in the documentation above). This will all come into play later.
Assumptions on the ALB side
For the purposes of this blog post, I’m going to take the following assumptions on the ALB configuration side, which need to be in place for the integration to work.
- There is a NSX-T Cloud Configured with the same vCenter and NSX-T account that you will be using in Aria Automation
- There is at least one IPAM profile assigned to the NSX-T cloud with at least one usable VIP network profile configured for allocating VIP IPs
- This VIP network profile name matches the network name in NSX-T
- There is a Service Engine group correctly configured
Now that everything is set up on the Aria Automation side (and ALB side) let’s move on to our use case!
NSX-T Template
Let’s take a look at the following NSX-T LB YAML Code
LB:
type: Cloud.NSX.LoadBalancer
properties:
routes:
- protocol: HTTP
port: 80
instancePort: 80
instanceProtocol: HTTP
algorithm: ROUND_ROBIN
healthCheckConfiguration:
healthyThreshold: 2
unhealthyThreshold: 3
protocol: HTTP
intervalSeconds: 15
urlPath: /
httpMethod: GET
port: 80
persistenceConfig:
type: COOKIE
cookieMode: INSERT
cookieName: CK-${uuid()}
cookieGarble: true
maxAge: 3600
maxIdle: 600
- protocol: TCP
port: 1000
instancePort: 1000
instanceProtocol: TCP
algorithm: LEAST_CONNECTION
healthCheckConfiguration:
healthyThreshold: 2
unhealthyThreshold: 3
protocol: TCP
intervalSeconds: 15
port: 1000
persistenceConfig:
type: SOURCE_IP
ipPurge: true
maxIdle: 60
network: ${resource.Cloud_NSX_Network_1.id}
loggingLevel: WARNING
instances: ${resource.Cloud_vSphere_Machine_1[*].id}
What do we have?
- Two virtual servers. One with TCP Port 1000, and another one with HTTP Port 80. Load Balancer Algorithm used for each of them is different
- Each virtual server has it’s own specific health check configuration as well as an application persistence configuration
- Load Balancer is using an existing NSX network in the deployment
- Load Balancer is taking the VM instances in the deployment as their pool members. Since VMs have a dynamic count, it is specified in that way in the assignment.
So how do we recreate this using ALB?
ALB Objects
Let’s first take a look at all the ALB objects that are available to use -> From https://docs.vmware.com/en/VMware-Aria-Automation/8.16/Using-Automation-Assembler/GUID-4844BFD9-18A5-4F8D-A53F-059DDE5DB0FF.html
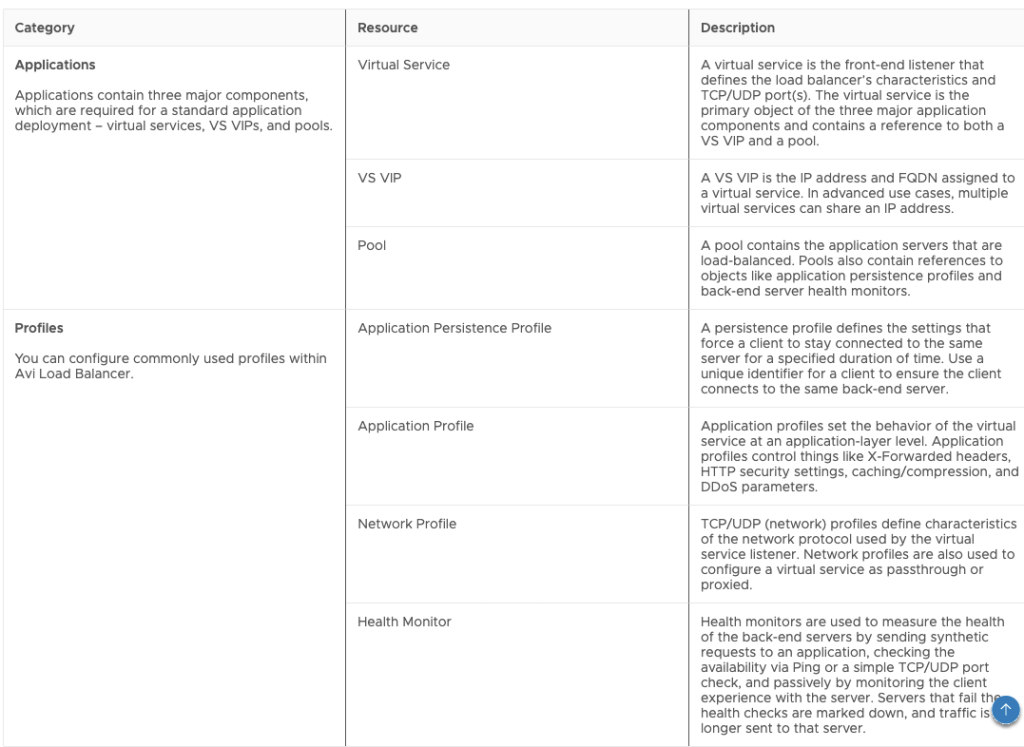
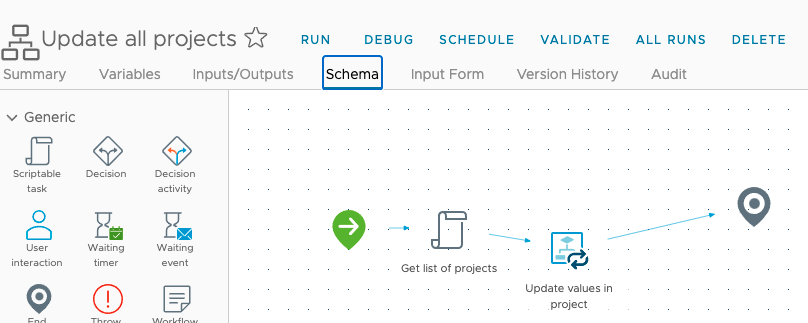
This is how these resources look in the Canvas:

In addition to this, we’re going to need to use the Allocation Helper for the cloud zone, which is also an available resource in the canvas.

Now that we have all of this, what does our NSX-T example translate to, with regards to objects?
We’re going to need:
- One VS VIP object for IP allocation (either static or dynamic)
- One Pool object per route
- One Virtual Service object per route
- One Monitor object per each individual health check configuration
- One Application Persistence object per each individual persistence configuration
- One Cloud Zone Helper object for placement
I know this sounds like a handful, but we will explain how to build each of these objects below. ALB provides much greater flexibility with regards to features, but that comes with the tradeoff of complexity.
It might take us longer to build what looked simpler in NSX-T, but once we’re over that hurdle, the amount of new possibilities is much greater!
Building the ALB Objects
While I’m going to explain each how to build each object here, there is a resource that’s invaluable for building all of this, which is the Swagger documentation of the ALB API.
You can access it by going to https://your_avi_controller_fqdn/swagger/#/
In the swagger documentation, you will be able to see each object’s schema model, as well as examples of creation. You might need to tweak and modify some of it to be able to use it in Aria Automation, but with some trial and error, success is very likely!
I will go about these objects in order by dependency – that means, an object has to be created first (it has to exist), to then be referenced by another object.
Cloud Zone Helper Object
This object will be used to apply constraint tags – In this example, I will match the tags that my VM objects have, so that there is matching with the vCenter – This one is pretty self explanatory, and it will be referenced by other objects
Allocations_CloudZone_1:
type: Allocations.CloudZone
properties:
accountType: avilb
constraints:
- tag: site:${input.site}
- tag: securityzone:${input.securityZone}
- tag: az:${input.availabilityZone}
VS VIP Object
VSVIP_1:
type: Idem.AVILB.APPLICATIONS.VS_VIP
properties:
name: VSVIP_${env.deploymentName}
description: Managed by Aria Automation
vrf_context_ref: T1-W1-Gateway-DR-01
tier1_lr: /infra/tier-1s/20f6q214-e8b3-4cb3-aaeb-6c07639ada23
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
vip:
- vip_id: 0
auto_allocate_ip: true
auto_allocate_ip_type: V4_ONLY
enabled: true
ipam_network_subnet:
network_ref: ${resource.Cloud_NSX_Network_1.resourceName}
Object Explanation:
- VSVIP requires a name – This is the name that you will see in the ALB console – you can set this to whatever name you want, but it makes sense to tie this to the deployment name so that you can identify it
- description can also be anything
- vrf_context_ref would be the name of the context ref in your NSX-T Cloud in ALB
- tier1_lr is the path to the T1 Gateway in your NSX-T instance – this uses the relative path in the NSX-T API as it is not an ALB Object:
- Note: this might change in future versions and might not be needed
- account is the ALB cloud account that you’re going to use – here is where you reference the Cloud Zone Helper created before
- vip is it’s own object, with the following properties
- Since we’re only using a single VIP, vip_id would be 0
- auto_allocate_ip is set to true because we want dynamic IP
- auto_allocate_ip_type is set to V4_ONLY because we’re doing IPV4
- enabled is set to true because we are enabling this VS VIP as we create it
- ipam_network_subnet is an object with a network_ref that maps to a VIP network profile in ALB
- Since this should match to a NSX-T network, we can use the network name in the deployment as an identifier
- This would be different if you were using a dedicated VIP segment. If that is the case, you can reference a specific VIP network profile name by name instead of using the name of the network resource in the deployment
Monitor Objects
For this deployment, we will have two monitor objects – one for each health check configuration
MONITOR_1:
type: Idem.AVILB.PROFILES.HEALTH_MONITOR
properties:
name: MONITOR_${env.deploymentName}_1
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
monitor_port: '80'
type: HEALTH_MONITOR_HTTP
successful_checks: 2
failed_checks: 3
send_interval: 15
http_monitor:
http_request: GET /
MONITOR_2:
type: Idem.AVILB.PROFILES.HEALTH_MONITOR
properties:
name: MONITOR_${env.deploymentName}_2
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
monitor_port: '1000'
type: HEALTH_MONITOR_TCP
successful_checks: 2
failed_checks: 3
send_interval: 15
Object Explanation:
- These objects also require names. To maintain consistency, we will be using the deployment name as an identifier
- Important – Since there will be more than one monitor, we’re using _NUMBER as an identifier as well. Then we can use the same numbering to map this to other objects (like Virtual Services, Pools or Profiles)
- You can also see that I’m using the same numbering for the objects within the YAML. This helps maintain consistency and makes it easier to understand what maps to what.
- account follows the same logic as in the VS VIP (and all the objects) – mapped to the Cloud Zone Helper object
- monitor_port is the port that is being monitored
- type is the monitor type – in this case, we have a HTTP and a TCP monitor
- successful_checks, failed_checks and send_interval are self explanatory
- http_request (which only shows up in the HTTP monitor) would be the method to use, and to what URL, in this case, we’re doing a GET to /
Application Persistence Objects
For this deployment, we will have two Application Persistence objects, one per application persistence configuration
PERSISTENCE_PROFILE_1:
type: Idem.AVILB.PROFILES.APPLICATION_PERSISTENCE_PROFILE
properties:
name: PERSISTENCE_${env.deploymentName}_1
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
persistence_type: PERSISTENCE_TYPE_CLIENT_IP_ADDRESS
ip_persistence_profile:
ip_mask: 0
ip_persistent_timeout: 60
PERSISTENCE_PROFILE_2:
type: Idem.AVILB.PROFILES.APPLICATION_PERSISTENCE_PROFILE
properties:
name: PERSISTENCE_${env.deploymentName}_2
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
persistence_type: PERSISTENCE_TYPE_HTTP_COOKIE
http_cookie_persistence_profile:
cookie_name: CK_${env.deploymentName}_2
timeout: 3600
is_persistent_cookie: false
Object Explanation
- Like every object, they need a name – following the same structure as the other objects
- account also follows the same structure
- persistence_type will depend on the type of persistence. We have one config for Source IP and one config for Cookie
- The object with the properties will be dependent on the persistence_type
- If you’re using Source IP persistence, the object will be ip_persistence_profile
- ip_mask is the mask to be applied to the client IP. This is 0 because we’re not applying a mask
- ip_persistent_timeout is the length of time before expiring the client’s persistence to a server, after its connections have been closed
- If you’re using Cookie Persistence, the object will be http_cookie_persistence_profile
- cookie_name is required and we can use the same naming structure as we use for the rest of the objects. I’m also making the number match to the number in the YAML resource for easier undertanding
- timeout is the maximum lifetime of any session cookie
- is_persistent_cookie controls the usage of the cookie as a session cookie even after the timeout, if the session is still open. With false, we’re allowing for this to happen
- If you’re using Source IP persistence, the object will be ip_persistence_profile
Pool Objects
For this deployment, we will have two Pool objects, one per route
POOL_1:
type: Idem.AVILB.APPLICATIONS.POOL
properties:
name: POOL_${env.deploymentName}_1
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
tier1_lr: /infra/tier-1s/20f6a214-e8b3-4bb3-aaeb-6c06639ada23
description: Managed by Aria Automation
default_server_port: '80'
health_monitor_refs:
- ${resource.MONITOR_1.name}
lb_algorithm: LB_ALGORITHM_ROUND_ROBIN
servers: '${map_by(resource.Cloud_vSphere_Machine_1[*].address, address => {"ip": {"addr": address, "type" : "V4"}})}'
application_persistence_profile_ref: /api/applicationpersistenceprofile/${resource.PERSISTENCE_PROFILE_1.resource_id}
POOL_2:
type: Idem.AVILB.APPLICATIONS.POOL
properties:
name: POOL_${env.deploymentName}_2
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
tier1_lr: /infra/tier-1s/20f6a214-e8b3-4bb3-aaeb-6c06639ada23
description: Managed by Aria Automation
default_server_port: '1000'
health_monitor_refs:
- ${resource.MONITOR_2.name}
lb_algorithm: LB_ALGORITHM_LEAST_CONNECTIONS
servers: '${map_by(resource.Cloud_vSphere_Machine_1[*].address, address => {"ip": {"addr": address, "type" : "V4"}})}'
application_persistence_profile_ref: /api/applicationpersistenceprofile/${resource.PERSISTENCE_PROFILE_2.resource_id}
Object Explanation
- name, account and description follow the same structure as the other objects
- tier1_lr is used in the same way as in the VS VIP object
- default_server_port is the default server port (would map to the internal port in the NSX-T Load Balancer)
- health_monitor_refs is an array of monitor references. Since our monitors are different, we are only going to use one item in the array, and this reference maps to the numbering used in the monitors
- This is why we kept numbering consistent – so MONITOR_1 maps to POOL_1 and MONITOR_2 maps to POOL_2
- servers maps to the servers in the deployment – the syntax uses map_by to allow for clustering as well as both attributes needed by the ip object, which are addr and type
- application_persistence_profile_ref maps to the application persistence object defined before
- Same scenario with the monitor – We keep numbering consistent so PERSISTENCE_PROFILE_1 maps to POOL_1 and PERSISTENCE_PROFILE_2 maps to POOL_2
Virtual Services Objects
For this deployment, we will have two Virtual Services objects, one per route
VIRTUALSERVICE_1:
type: Idem.AVILB.APPLICATIONS.VIRTUAL_SERVICE
properties:
name: VS_${env.deploymentName}_1
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
vrf_context_ref: T1-W1-Gateway-DR-01
enabled: true
services:
- enable_ssl: false
port: '80'
traffic_enabled: true
vsvip_ref: /api/vsvip/${resource.VSVIP_1.resource_id}
pool_ref: /api/pool/${resource.POOL_1.resource_id}
application_profile_ref: /api/applicationprofile?name=System-HTTP
network_profile_ref: /api/networkprofile?name=System-TCP-Proxy
VIRTUALSERVICE_2:
type: Idem.AVILB.APPLICATIONS.VIRTUAL_SERVICE
properties:
name: VS_${env.deploymentName}_2
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
vrf_context_ref: T1-W1-Gateway-DR-01
enabled: true
services:
- enable_ssl: false
port: '1000'
traffic_enabled: true
vsvip_ref: /api/vsvip/${resource.VSVIP_1.resource_id}
pool_ref: /api/pool/${resource.POOL_2.resource_id}
application_profile_ref: /api/applicationprofile?name=System-L4-Application
network_profile_ref: /api/networkprofile?name=System-TCP-Fast-Path
Object Explanation
- name and account follow the same structure as in the other objects
- vrf_context follows the same structure as in the VS VIP object
- enabled is set to true because we want this service to be enabled
- services is an array – but since we’re mapping this to a single pool, we will only have one service in the virtual service
- We’re using the same port as the internal port, and enable_ssl is set to false
- traffic_enabled is set to true to allow for traffic
- vsvip_ref references the VS VIP object previously created – since there is a single VSVIP object, both virtual services will reference it
- pool_ref references the pool that has the members for this service. Using the same numbering strategy as before, VIRTUALSERVICE_1 references POOL_1 and the same thing with number 2
- application_profile_ref will vary based on the protocol – To align with NSX-T LB:
- for HTTP it will reference System-HTTP
- for TCP it will reference System-L4-Application
- network_profile_ref will also vary based on the protocol – To align with NSX-T LB
- for HTTP it will reference System-TCP-Proxy
- for TCP it will reference System-TCP-Fast-Path
Complete object
Adding up everything we created before, we end up with this YAML code!
Allocations_CloudZone_1:
type: Allocations.CloudZone
properties:
accountType: avilb
constraints:
- tag: site:${input.site}
- tag: securityzone:${input.securityZone}
- tag: az:${input.availabilityZone}
VSVIP_1:
type: Idem.AVILB.APPLICATIONS.VS_VIP
properties:
name: VSVIP_${env.deploymentName}
description: Managed by Aria Automation
vrf_context_ref: T1-W1-Gateway-DR-01
tier1_lr: /infra/tier-1s/20f6q214-e8b3-4cb3-aaeb-6c07639ada23
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
vip:
- vip_id: 0
auto_allocate_ip: true
auto_allocate_ip_type: V4_ONLY
enabled: true
ipam_network_subnet:
network_ref: ${resource.Cloud_NSX_Network_1.resourceName}
MONITOR_1:
type: Idem.AVILB.PROFILES.HEALTH_MONITOR
properties:
name: MONITOR_${env.deploymentName}_1
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
monitor_port: '80'
type: HEALTH_MONITOR_HTTP
successful_checks: 2
failed_checks: 3
send_interval: 15
http_request: GET /
MONITOR_2:
type: Idem.AVILB.PROFILES.HEALTH_MONITOR
properties:
name: MONITOR_${env.deploymentName}_2
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
monitor_port: '1000'
type: HEALTH_MONITOR_TCP
successful_checks: 2
failed_checks: 3
send_interval: 15
POOL_1:
type: Idem.AVILB.APPLICATIONS.POOL
properties:
name: POOL_${env.deploymentName}_1
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
tier1_lr: /infra/tier-1s/20f6a214-e8b3-4bb3-aaeb-6c06639ada23
description: Managed by Aria Automation
default_server_port: '80'
health_monitor_refs:
- ${resource.MONITOR_1.name}
lb_algorithm: LB_ALGORITHM_ROUND_ROBIN
servers: '${map_by(resource.Cloud_vSphere_Machine_1[*].address, address => {"ip": {"addr": address, "type" : "V4"}})}'
application_persistence_profile_ref: /api/applicationpersistenceprofile/${resource.PERSISTENCE_PROFILE_1.resource_id}
POOL_2:
type: Idem.AVILB.APPLICATIONS.POOL
properties:
name: POOL_${env.deploymentName}_2
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
tier1_lr: /infra/tier-1s/20f6a214-e8b3-4bb3-aaeb-6c06639ada23
description: Managed by Aria Automation
default_server_port: '1000'
health_monitor_refs:
- ${resource.MONITOR_2.name}
lb_algorithm: LB_ALGORITHM_LEAST_CONNECTIONS
servers: '${map_by(resource.Cloud_vSphere_Machine_1[*].address, address => {"ip": {"addr": address, "type" : "V4"}})}'
application_persistence_profile_ref: /api/applicationpersistenceprofile/${resource.PERSISTENCE_PROFILE_2.resource_id}
VIRTUALSERVICE_1:
type: Idem.AVILB.APPLICATIONS.VIRTUAL_SERVICE
properties:
name: VS_${env.deploymentName}_1
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
vrf_context_ref: T1-W1-Gateway-DR-01
enabled: true
services:
- enable_ssl: false
port: '80'
traffic_enabled: true
vsvip_ref: /api/vsvip/${resource.VSVIP_1.resource_id}
pool_ref: /api/pool/${resource.POOL_1.resource_id}
application_profile_ref: /api/applicationprofile?name=System-HTTP
network_profile_ref: /api/networkprofile?name=System-TCP-Proxy
VIRTUALSERVICE_2:
type: Idem.AVILB.APPLICATIONS.VIRTUAL_SERVICE
properties:
name: VS_${env.deploymentName}_2
account: ${resource.Allocations_CloudZone_1.selectedCloudAccount.name}
vrf_context_ref: T1-W1-Gateway-DR-01
enabled: true
services:
- enable_ssl: false
port: '1000'
traffic_enabled: true
vsvip_ref: /api/vsvip/${resource.VSVIP_1.resource_id}
pool_ref: /api/pool/${resource.POOL_2.resource_id}
application_profile_ref: /api/applicationprofile?name=System-L4-Application
network_profile_ref: /api/networkprofile?name=System-TCP-Fast-Path
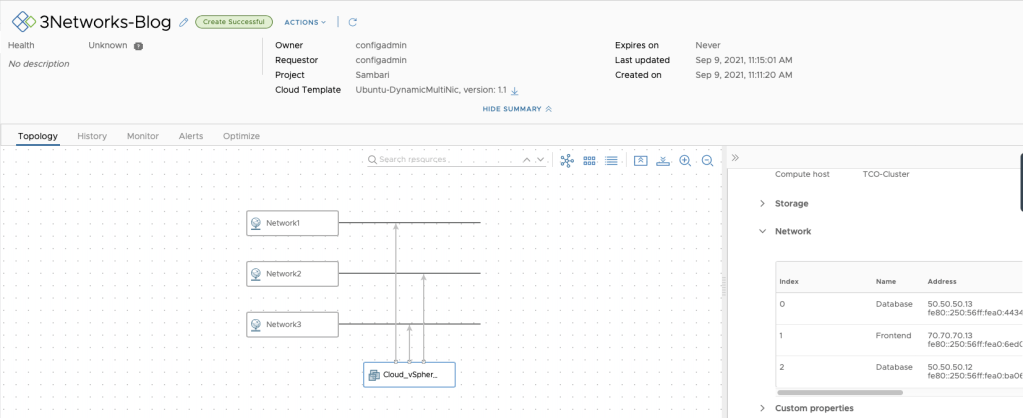
Adding this code to a blueprint that already has a VM Object and a Network Object will let us do a deployment that will look like this!

Hooray!!!!
Some Caveats and Final Thoughts
- Currently, the only supported way to update ALB objects using vRA is via Iterative Updating – this means, applying a new YAML code to the deployment
- This can be done by changing the blueprint and then updating the deployment, or by using blueprint-requests API to send new YAML code to the deployment
- Official documentation (linked above) and the Swagger are your best friends – There are many more options that can be configured based on your business needs!
- The official blog by Scott McDermott also has some examples that could be useful! -> https://blogs.vmware.com/management/2024/02/deploy-avi-load-balancer-with-aria-automation-templates.html
I hope you find this useful! If you do, please leave a comment, and don’t hesitate to reach out with any questions!